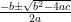Las computadoras están diseñadas de fábrica para poder realizar las operaciones que se necesitan para hacer una calculadora simple, de ahí que puede ser buena idea que uno de los primero programas para alguien que quiere empezar sea una calculadora, ya que no es necesario implementar tantas otras cosas como en otros proyectos. Desde luego, pueden usarse librerías para no tener que implementar todo en tales casos, pero al principio puede dejarse para después el tema de las librerías.
Y cuando se me ocurrió este posteo lo primero que hice fue buscar en google para ver si no era algo demasiado hecho. Lo que me llamó la atención es que si bien hay varias páginas que muestran cómo hacer una calculadora, las que se trae como primero resultados muestran que nada cómo hacer una interfáz para que un usuario escriba dos números y una operación para después pedirle a la computadora el resultado y mostrarlo en la pantalla.
En el otro extremo hay una página que muestra lo siguiente código (en python):
print(eval(input()))
Ese ejemplo incluye una calculadora, pero también mucho más, porque la función eval lo que hace es justamente pasarle al intérprete de python lo que sea para que lo evalúe. Y si es una expresión artmética lo va a calcular, pero puede eveluar cualquier expresión de python. Eso puede implicar riesgos para la seguridad del sistema, asi que no es aconsejable tampoco… (imagínense pasarle a eval cosas como exec('import os; print(os.listdir(os.getenv("HOME")))') o peor, que borren archivos, etc.
La idea entonces es hacer algo que no es ni una cosa ni la otra, tratando en el camino de entender qué vamos haciendo, hasta cierto punto al menos. Un programa que recibe una expresión aritmética como «7 + 8 * 6» y devuelva como resultado el número que esa expresión denota. O sea, a diferencia del primer ejemplo podemos hacer más de una operación «por cuenta» y a diferencia del segundo sólo vamos a resolver operaciones ariméicas y no cualquier expresión de python.
La interfáz es bien simple: nuestro usuario va a llamar una función que vamos a llamar calcu y a pasarle una string donde esté la expresión, algo como calcu("21 * 24 / (4 + 3)"). Y si la expresión está mal formada directaente vamos a fallar de forma poco amigable (en otro posteo podemos hacer algo mejor en ese aspecto pero en este no vamos a mantener simples).
Las operaciones binarias a soportar son +, -, *, /, ^ y también vamos a poder usar numero negativos que empiecen con - unario (más adelanta más sobre esto). Las prioridade de agrupación son las habituales, o sea + tiene menos prioridad que *, etc., y usamos los préntesis si queremos un orden distinto al de la convención como (3+4)*5. Vamos a evaluar una sola expresión y no vamos a usar variables, cosa que también podríamos ver, quizá, después.
Pero qué es lo que vamos a considerar una expresión válida? Cómo definimos cuáles son las expresiones que están bien y las que no? Bueno quizá si uno de la nada quiere especificar esto puede ser bastante complicado dar con una respuesta (el lector podría intentar dar con alguna forma por su cuenta), pero por suerte es un problema ya resuelto y la solución se llama notación de Backus-Naur.
Puede leerse el artículo de wikipedia para entender mejor pero lo que necesitamos saber por ahora es que cuando usamos un := lo que está a la izquierda puede reemplararse por lo de la derecha y cualquier expresión que pued obtenerse así es válida, siempre que empiece del «símbolo distinguido». Vamos mejor a un ejemplo ya que la idea es simple aunque dificil de resumir en una línea. El ejemplo es justament nuestra gramática de expresiones aritméticas.
E := E + T
| E - T
| T
T := T * F
| T / F
| F
F := (E)
| Num
| -Num
Esta gramática es parecida (pero distinta) a la que está en esta página a la que el lector puede ir a ver por si le sirve para entender cómo se usa. Pero trato de explicar brevemente (ya que en realidad no es el tema de este posteo).
La idea es que una expresión pertenece a nuestra gramática siempre y cuando haya una forma de «generarla» partiendo del símbolo E y llegando a algo done de no haya más que +, -, *, /, (, ) y Num donde Num en realidad significa una número (si el lector sabe de regex, sería algo que matchee ([0-9]*[.])?[0-9]+ por ejemplo).
Cómo se genera una expresión en base a otra? Bueno, siempre podemos reemplaza cualquiera de los símbolos a la izquierda de := (el | es una manera abreviada de decir lo mismo) por lo que aparece a la derecha, ejemplo: E => E - T o (E) => (F). Nótese en el segundo ejemplo que (E) aparece a la derecha también, pero lo que nos importa es que como E := F entonces aplicamos esto a (E) y nos queda (F).
Es decir, usamos los símbolos E, T, F por un lado y los comunes +. -. *, ... etc. Num en realidad se refiere a cualquier número. Los E, T, F se llaman «no terminales» porque en sí mismos nunca están en una expresión, hay que derivarlos, del siguiente modo: para generar una expresión partimos del síbolo E (es nuestro símbolo distinguido) y aplicamos las reglas todas las veces que sea necesario hasta llegar a algo que no tenga más «no terminales». De E tenemos 3 opciones E + T, E - T y T. Y después tenemos que seguir, por ejemplo:
E -> E * T -> T * T -> F * T -> (E) * T -> (E + T) * T -> (T + T) * T ->...-> (Num + Num)
* Num
La definición de esta gramática es importante para el usuario porque una misma expresión puede estar bien o mal según qué gramática sea. No siempre los usuarios están al tanto de estas diferencias. Por ejemplo, si buscamos «calculadora» en google el mismo google nos da una calculadora en la cual no podemos escribir por ejemplo - -2. En python, por el contrario, - -2 es una expresión válida, a saber -(-2) que equivale a 2. Incluso podemos escribir --2 y es igual. Pero esto no ocurre así en todos los lenguajes. Por ejemplo, el shell de java interpreta esto como un error:
jshell> --2
| Error:
| unexpected type
| required: variable
| found: value
| --2
| ^
#
Algo similar ocurre con la calculadora bc:
bc 1.07.1
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006, 2008, 2012-2017 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
--2
(standard_in) 1: syntax error
En haskell es más particular, pues se ignora la expresión dado que -- es la forma de inicial un comentario…
En nuestro caso vamos a adotar la decisión de no admitir más de un - consecutivo para ivnertir el signo de un número (tal como especifica nuestra gramática): después de todo no hace falta. O sea hacemos como la calculadora del buscador. Y si el usuario quiere igual puede hacer -(-2).
Estas diferencias provienen de la ambigüedad de usar un mismo símbolo - para dos cosas: sumar, cambiar el signo. Y demás de que en realidad el usuario no escribe directamente en nuestra gramática. Él escribe caracteres, eso es lo que leemos, y tenemos que hacer una pimera traducción de los caracteres a nuestr a gramática. Es decir, nosotros leemos el símbolo - que por sí mismo no nos dice cuál de los dos significados tiene. Por suerte es facir saberlo por el contexto, an particular, por lo que hay antes. Observando nuestra gramática vemos que es una resta binaria sólo si viene inmediatamente después de una E y es el cambio unario de signo si empieza un F. Tenemos que mirar un poco más hasta ver qué símbolos terminales pueden estar en ambos contextos, y es fácil llegar a que la última parte de una E puede ser un Num o un ) y entonces si vemos un - después de alguno de estos dos sabemos que es un asuma. Y F tenemos después de *, / o (, con lo cual la ambugüedad se resuelve leyendo sólo lo último que se haya leído antes.
Vamos entonces a hacer dos pasadas: en la primera leemos los caracters de a uno y devolvemos una expresión válida en nuestra gramática donde cada elemento es un «símbolo terminal» de la misma, es decir, alguno de los operadores, paréntesis o un número. Después vamos a leer esta cadena resultante y hacer la cuenta.
Un último comentario. Dije ya que si la entrada no corresponde a la gramática no nos interesa dar un resultado útil. Por ejemplo «1 1» no tiene sentido así que no nos ocupamos de dar alguna respuesta en tales casos. Pero puede ocurrir que la entrada sea correcta desde el punto de vista sintáctico y así y todo no tenga sentido. Es el caso de entradas como «1 / 0». En ese caso se obtiene correctamente E -> T -> T / F -> F / F -> 1 / F -> 1 / 0. Pero matemáticamente no tiene sentido. Hacer una gramática que no acepte ese conjunto de entradas y sí el resto no valdría la pena. Lo que vamos a hacer es pasarle a python la cuenta y python nos va a tirar una excepción que vamos a dejar pasar.
Ahora sí, entonces, podemos pasar al algoritmo. En primer lugar, el traductor de caracteres a tokens. La idea es simplemente leer salteando los espacios. Si es una operación, entonces agregarla como token, si es el primer caracter de un número, leer todo el número y agregarlo. El único detalle a tener en cuenta es la ambigúedad de - que se maneja como se dice arriba. El resultado es una lista de string, cada elemento de la lista es un token (o un lexema) de nuestra gramática:
def read_number(s, i):
return next((k for k,e in enumerate(s[i+1:]) if e in " +-*/^()"), len(s[i:]) - 1) + i + 1
def read_expression(s):
tokens = []
last = "^"
i = 0
while i < len(s):
if s[i] == " ":
i = i + 1
pass
elif s[i] in "+*/^()" or (s[i] == "-" and last in "0123456789)"):
tokens.append(s[i])
last = s[i]
i = i + 1
else:
ix = read_number(s,i)
tokens.append(s[i:ix])
last = s[ix-1]
i = ix
return tokens
La segunda parte es un poco más complicada. Usamos dos pilas, una con las operaciones y otra con los «valores». Estos valores son o bien los número que vamos leyendo o aplicaciones parciales de la cuenta que queremos hacer. El tema es que para aplicar una operación necesitamos comparar la prioridad del operador con los que estén a ambos lados, y por eso los guardamos para hacer hasta que podemos comparar. Ahi entonces «reducimos» lo cual significa hacer la operación y su resultado se va guardandod en la pila de los valores:
priority = {
'+': 1,
'-': 1,
'*': 2,
'/': 2,
'^': 3,
'(': 0
}
opsfun = {
"+" : lambda x, y: x + y,
"-" : lambda x, y: x - y,
"*" : lambda x, y: x * y,
"/" : lambda x, y: x / y,
"^" : lambda x, y: x ** y
}
def reduceWhile(ops, vals, condition):
while ops and condition(ops[-1]):
vals[-1] = opsfun[ops.pop()](vals[-2], vals.pop())
def calcu(tokens):
ops, vals = [], []
expr = read_expression(tokens.strip())
for c in expr:
if (c == '('):
ops.append(c)
elif (c == ')'):
reduceWhile(ops, vals, lambda last: last != '(')
ops.pop()
elif c not in ["+", "-", "*", "/", "^"]:
vals.append(float(c))
else:
reduceWhile(ops, vals, lambda last: priority[c] <= priority[last])
ops.append(c)
reduceWhile(ops, vals, lambda x: True)
return vals[-1]
Y nuevamente, el posteo me quedó más largo de lo que imaginé en un principio y se extendería por ende demasiado si sigo. Por eso lo dejo acá y eventualmente lo continuaremos en comentario u otros posts (probablemente quiera hacer alguno con un enfoque completamente distinto, menos «machine-oriented» y más teórico usando las teorías sobre parsing.
El código de este post puede verse mejor en este gist.
Algunas veces tiene lugar la duda sobre qué lenguaje elegir. Por ejemplo, al empezar un nuevo proyecto. O incluso en una materia de la facultad pueden querer proponer un lenguaje para los trabajos prácticos. Ahora mismo, alguien que empieza a programar puede estar pensándolo.
Lo que está claro es que siempre es elegir un lenguaje para algo en particular, no es que un programador esté atado a uno. Y si bien algunos programadores ponen cosas como c++ developer en linkedin y algunas búsquedas también apuntan por ejemplo a un java developer, etc., lo cierto es que lo que tiene que aprender un programador no es un lenguaje de programación particular sino que es algo más amplio. Son ideas comunes a todos los lenguajes, ideas que se repiten, o hasta a veces aspectos del hardware por poner un ejemplo. En resumen, un lenguaje es una herramienta, no es ni el principio ni el fin de la programación.
No conozco programadores con alguna experiencia que programen únicamente en un único lenguaje. De hecho, Bjarne Stroutroup quien dedicó su carrera a un lenguaje, dijo queNadie debería llamarse a sí mismo un profesional si conoce sólo un lengauje y que 5 es un buen número de lenguajes para aprender razonablemente bien. Y termina proponiendo 5 entre C++ (obvio), Java, quizá Python, Ruby y JavaScript, C y C#.
Por otra parte, Larry Wall responde a la misma pregunta (de cuáles son los 5 lenguajes que recomienda aprender) agregando un dato no menor: eso va cambiando con el tiempo. Y pone por ejemplo que cuando empezó la respuesta hubiera sido Fortran, Cobol, Basic, Lisp y quizá APL. Pero que hoy en día (lo dijo en 2011) era probablemente más importante saber JavaScript. Menciona también Java (el Cobol del SXXI dice…, vean el video que está muy bien). A Haskell, a C y finalmente a Perl.
Para el lector que está empezando en este momento esto no es un problema, porque no es que tenga que tomar una decisión como quien elije una carrera. Se trata más bien de una especie de charla de sobremesa entre programadores. O sea, inevitablemente un programador termina conociendo al menos 5 lenguajes (qué tan bien depende de cuanto le guste su profesión o al menos ese aspecto) e inevitablemente va a verse involucrado en alguna conversación sobre cuál es más conveniente con colegas.
Además, así como a veces se elije, otras no, y hay que usar el que ya se eligió con anterioridad (probablemente esta sea la razón por la que ese usa tanto java …).
Y lo peor que puede hacer alguien es perder tiempo con este tipo de dudas.
Lo bueno es que (como dice Stroustroup) hay lenguajes que se parecen y aprender uno es también aprender otros. Así que acá vamos a optar por un camino distinto al de muchos libros o cursos introductorios de atarse a un lenguaje particular, y vamos a ver algunos, no uno solo, y vamos a tratar de entender eso que tienen en común que justamente hace que aprender uno implique aprender el otro. Eso no significa que si, por ejemplo, uno tiene mucha práctica con java despúes se pone a escribir javascript de memoria sin consultar nada en internet o los libros. Siempre que uno ve un lenguaje por primera vez se tiene que pasar algún tiempo mirando su sintaxis, sus librerías y cosas así. Y también es cierto que por más que uno tenga mucha experiencia con un lenguaje va a tener que estar buscando cosas en internet (incluso ya sabidas pero no recordadas con total exactitud) o incorporar los cambios que traen las nuevas versiones.
Dicho esto es obvio que no voy a hablar de todos los lenguajes que existen sino solo de un subcojunto bastante menor. Por ejemplo, es poco probable que hable de cobol acá. Pero la idea es hacer una introducción para quienes quieren empezar, y que sirva incluso para quienes vayan a usar lenguajes de los que acá ni aparecen ejemplos.
Así que pasemos a algunos comentarios generales.
Paradigmas de los lenguajes de programación
Esto de los paradigmas si bien se lo encuentra bastante no es un concepto formal y del todo claro. En algunos puntos hay matices. Pero hay aspectos que sí son claros. Y los lenguajes de programación (y sus usiarios!) a veces se caracterizan por estar más encuadrados a un paradigma. Además, creo que es justamente lo que los lenguajes buscan implementar de un paradigma una de las cosas hace que se parezcan tanto entre sí. Por ejemplo, en uno de los «paradigmas», llamado funcional existe la idea de funciones de alto orden que fue incorporada por muchos lenguajes de programación (en particular por todos los nuevos), incluso lenguajes que originalmente eran los abanderados de otro paradigma, como el de programación orientada a objetos. El punto al que voy es que una vez que uno entiende esa idea y qué tiene de bueno tener ese tipo de funciones y cómo usarlas, etc., después no cuesta nada ver los detalles de sintaxis para hacerlo en los lenguajes que lo permiten, como pueden ser C++, Kotlin, JavaScript, Python, etc. etc. O sea, aprender y estár cómodo usando funciones de alto orden es un herramienta en sí misma, que después se puede aprovechar con cualquier lenguaje comúnmente usado hoy por hoy.
Por otra parte este es un punto que también se puede dar en discusiones de sobremesa (y probablemente puedan ser más acaloradas que las de los lenguajes?). Qué paradigma usar o cuál es mejor? Yo voy a tratar de evitar ir directamente a esta cuestión porque suele basarse en opiniones. Y obvio que tengo mis opiniones al respecto, como todo el mundo, pero mi idea es ir exponiéndolas cuando sea necesario y a medida que le puedan llegar a servir a quien esté aprendiendo.
Pero me parece importante hacer notar un punto central en todos estos debates. A saber, que todo esto se da de esta manera porque programar no es una actividad solitaria. Uno puede programar solo y es muy divertido (tal vez sea más divertido…) pero en la vida real, por ejemplo en la industria, se trabaja en un equipo donde pueden haber distintos puntos de vista e inevitablemente existirán veces donde unos se impongan sobre otros (este punto es particularmente de interés). Esto puede ocurrir en cosas muy claras como la elección de un lenguaje de programación para hacer algo. O en una code review puede haber una discrepancia que tenga que ver con si hacer algo con un estilo funcional o no, por ejemplo. O mismo dentro de un paradigma se dan diferencias: tal tarea es responsabilidad de qué clase? usamos o no tal patrón de diseño? etc.
Quizá alguna vez alquien interprete la historia de la programación como la dialéctica de la lucha entre paradigmas. Pero en cualquier caso no ese el tema de este post.
Ya iremos viendo qué son esas cosas que mencioné sin introducir como funciones de alto orden, clases, patrón de diseño, el punto era ilustrar que son cosas del día a día, además de discusiones a veces improductivas. Y que en ocasiones se trata más de una habilidad social puesta en juego en una argumentación para adoptar un enfoque que uno prefiere o no dentro de un equipo. Y que conocer todo lo que está relacionado a los paradigmas sirve para, por ejemplo, no perder tiempo inventando lo que ya se hizo o intentando enfoques que se demostraron mejorables, aunque también para poder comunicarse mejor en esas discusiones para entender mejor y que a uno lo entiendan mejor. Además de que muchas de estas cosas están harcodeadas y conocerlas facilita mucho la comprensión del código que uno tiene que leer al programar. Y me permito una nota sobre esto: reinventar la rueda, acción que es tan menospreciada, puede ser el origen de un punto de vista creativo y que permita expandir los horizontes, pregúntenle a Frege si no.
Todos los lenguajes de programación tienen en común el permitirle a alguien (o sea al programador) que le diga a la computadora lo que tiene que hacer. Es decir, darle algo para hacer. Esto es común a todos. Pero después cuando vemos cómo se hace esto las cosas difieren.
Paradigma imperativo
Una subrutina puede verse como una extensión del lenguaje máquina de la computadora.
– Donald Knuth
Al principio de la computación, las instrucciones eran las que traía la maquina (el hardware) de fábrica, el set de instrucciones del que hablamos en otro post. Hoy ya no es así, (casi?) nadie programa escribiendo lenguaje máquina ni assembler. Por qué cambió esto? Bueno, porque es mucho más fácil, eficiente, seguro, y probablemente unos cuantos etcéteras, hacerlo con abstracciones más modernas como las que se usan hoy. Por qué no se hardcodean esas abstracciones? Bueno, esa pregunta habría que hacérsela a los fabricantes de hardware. Pero lo interesante es ¿Qué nos permite hacerlo de esta otra manera? Y la respuesta es: el software. Entre la maquina procesando instrucciones de su instruction set y las expresiones que escribe un programador hay software en el medio que se encarga de traducir de un lenguaje a otro. Ese software es desarrollado y mantenido por programadores, pero probablemente la mayoría de los programadores se dedican al menos el día de hoy a usar esos programas y escribir aplicaciones con los lenguajes de más «alto nivel», o sea, los que se alejan más de la máquina porque tienen abstracciones en el medio implementadas en software por otros programadores.
Una de estas abstracciones (bien básica) es la de variable. En computación y sobre todo en el paradigma imperativo (en otros paradigmas es diferente), una variable es algo diferente a lo que es en matemática. En matemática las variables son incógnitas, o bien conjuntos con incógnitas. En una ecuación como x = x2 simplemente denota un conjunto de números que reemplazándolos por la x hacen que la expresión tenga sentido. En este caso, que usando un poquito de álgebra nos dá que es equivalente a 0 = x( − 1 + x) vemos que la ecuación vale si x ∈ {0, 1}.
En computación imperativa, es una cosa totalmente diferente. Una variable no es más que el nombre de un lugar donde guardo algo. Así de simple. Para ver esto podemos abrir un intérprete interactivo de python, Así, por ejemplo, podemos escribir:
>>> x =2
Y con eso no estamos denotando el número 2 o el conjunto que contiene al número dos (ni tampoco eso es equivalente a 0 = 2 − x. Cuando escribimos eso en python estamos diciéndole a la computadora: guardame en este lugar, x, el
número 2.
También podemos escribir, en python:
>>> x = x * x
Esto tampoco tiene nada que ver con una ecuación matemática. Le estamos diciendo a la computadora que eleve el valor guardado en x al cuadrado y que al resultado lo guarde en x, o sea en el lugar de la memoria que llamamos x. Esto tiene sentido porque la parte de la derecha ocurre primero y después se guarda el resultado de la cuenta en x, pisando el valor que había antes, que era un 2 porque lo habíamos puesto ahí.
Dije que «la parte de la derecha ocurre primero». Esa es una forma de hablar, mucho mejor es decir que primero se ejecuta la expresión de la derecha y su resultado se guarda en la variable que hay a la izquierda.
Es fácil ver esto. Si uno quiere usar la variable sin antes haberle «hecho saber» a la computadora que ese nombre era el de una variable, la computadora nos va «tirar un error». Y digo tirar un error en vez de devolver un error porque hubiera devuelto algo si nosotros pedíamos eso que devolvía, pero tratándose de un error es algo distinto: la ejecución se interrumpe y se avisa que no se pudo continuar con lo que se estaba.
Así, si no hubiéramos puesto algo en ese variable la cosa no hubiera funcionado:
>>> y = y * y
El intérprete de python nos va a decir: NameError: name 'y' is not defined. Es decir: nunca me dijiste que haga lugar en la memoria para un objeto con
ese nombre.
El signo =, entonces, se usa en python para guardar objetos en la memoria. Para la igualdad se usa este otro: ==, o sea dos símbolos de igual seguidos. Tal vez la elección de estas convenciones no haya sido la mejor, y puede ocurrir que por un error de tipeo uno escriba = en vez de == y vice versa y después pierda mucho tiempo con un error inentendible en un programa. Pero esta es la elección de muchos lenguajes y resulta ser uno de esas cosas (trivial en este caso) que son comunes a muchos lenguajes.
Pero igualmente, usando == estamos en la misma. Si escribimos únicamente
>>> y == y * y
tenemos un error de nombre y si escribimos
>>> y =2>>> y == y * y
Simplemente vamos estar escribiendo 2 es igual a 2 + 2, y lo que vamos a obtener es que es falso. Cuando lee y == y * y la maquina empieza preguntando ¿qué es y? y es 2, porque guardamos eso arriba. O sea que queda 2 == 2 * 2. Después evalúa2 * 2. Las computadoras son muy buenas para eso, es 4. Finalmente evalúa 2 == 4, algo que también sabe hacer: eso es falso, 2 no es 4. Entonces termina diciendo eso mismo:
>>> x =2>>> x == x * xFalse
Acá no estamos volviendo a escribir en x después de haber escrito 2 porque == no escribe, el que escribe es =. La operación que se realiza cuando se lee ese símbolo se llama asignación y consiste entonces en leer lo que hay a la derecha de =, evaluarlo, y finalmente guardarlo en la variable que hay a la izquierda, que como dijimos es el nombre que le pusimos a una parte de la memoria para acordarnos y poder pedirlo más tarde para usarlo. Esta claro entonces que no da lo mismo qué va a la izquierda y que a la derecha del =, es decir x = x * x no es lo mismo que x * x = x. En efecto:
>>> x * x = x x * x = x^SyntaxError: cannot assign to operator
El intérprete acá nos dice que no puede «asignar a un operador». Se refiere al operador * con el que multiplicamos, ya que no es el nombre de ningún lugar en la memoria. Cuando algo puede estar a la izquierda de =, como la variable x, se dice que es un lvalue (l por left). Cuando algo puede estar a la derecha se dice que es un rvalue (r por right).
Pero entonces volviendo a nuestro problema inicial ¿hay manera de que la computadora nos averigüe lo que la fórmula matemática estaba expresando, o sea la raíces de la ecuación x = x2?
Bueno en este caso podemos por ejemplo usar «la resolvente de la cuadrática» que vemos en la secundaria
y esas son todas operaciones que la computadora «ya sabe» hacer. Pero es importante notar que existe una gran diferencia entre la expresión matemática, que directamente está denotando el conjunto de soluciones, independientemente de si alguien sabe o no cuáles son, y la expresión como programa, que codifica instrucciones para que ejecute una máquina. El programa tiene que encontrar la forma de encontrar los resultados, no le basta con denotarlos (ni simplemente decir que existen). Y obviamente es el programador el que tiene que buscar cómo.
Para eso tiene que usar las operaciones que provee. Veamos el siguiente programa que calcula el máximo común divisor entre 72 y 54 y el de 123 y 42. Elijo un ejemplo que puede parecer medio «matemático» para empezar pero no porque la programación sea frecuentemente resolver este tipo de problemas (ya que lo común es usar soluciones ya escritas para estos casos), sino porque para empezar al haber pocos conceptos que se asumen disponibles para la programación no queda más remedio de usar los más básico: números y operaciones sobre números.
En ese bloque, además del operador de asignación que ya mencionamos, se usa el % (o módulo), != («es distinto que»), or (u o) y la resta -. Por último se usa el while.
Lo primero que hacemos es guardar el número 54 en mcd. Esto es porque el mcd entre 54 y 72 necesariamente tiene que ser menor o igual que el mínimo de ambos, o sea que 54. Después usamos un loop, llamado while. while sirve para repetir un bloque de código siempre que una determinada condición no se cumpla. En este caso la condición es 54 % mcd != 0 or 72 % mcd != 0. El bloque en cuestión, que en este caso es mcd = mcd - 1 se va a repetir siempre que el valor ne mcd no divida a 54 o a 72. O sea, va a frenar si (únicamente si) divide tanto a uno como al otro. Esta es la condición que esperamos que cumpla porque es la que cumplen todos los divisores comunes a ambos números. Cada vez que la condición no se cumple, probamos con el número entero inmediatamente más chico. Esto lo hacemos «decrementando» (lo contrario de incrementar) el valor que hay en mcd.
¿Cómo sabemos que este programa funciona correctamente? Un programa puede ser incorrecto de al menos tres maneras en un caso como este. Puede computar un número distinto al que queríamos, o puede «colgarse» y no terminar nunca. Esto en particular es un riesgo cierto cada vez que usamos while. Y también puede interrumpirse debido a algún error.
En este caso sabemos que el programa no se va a colgar por el siguiente motivo. mcd empieza siendo 54 y va bajando de a uno: 54, 53, 52, … Si este programa se colgara sería porque mcd bajaría indefinidamente sin que se cumpliera la condición. Pero esto no puede ser, porque si bajara indefinidamente eventualmente valdría 1, y tanto 54 % 1 como 72 % 1 dan 0, y en tal caso se saldría del while. Esto significa, de paso, que mcd nunca va a llegar a 0. Esto es importante, porque si llegara a 0, entonces se produciría un error:
>>> mcd =0>>>54% mcdTraceback (most recent call last): File "<stdin>", line 1, in<module>ZeroDivisionError: integer division or modulo by zero
Este error haría que el programa se interrumpa y termine pero sin calcular ningún valor ni nada. Pero como dijimos, mcd no llega a 0 y en cambio sí está definida para todos los valores mayores o igual a 1.
Por otra parte, sabemos que el máximo común divisor tiene que ser menor o igual que 54, porque ningún número mayor a 54 puede ser divisor de 54. Y como vamos de a uno desde 54 hasta 1, el primero que encuentre va a ser el mayor de todos.
Así, el programa es «correcto», en el sentido en que computa el número buscado. Sin embargo amerita algunos comentarios.
En primer lugar vemos lo que se llama código repetido. Casi calcadas tenemos las mismas 4 líneas. Esto es algo malo y mejorable. Es mejorable porque todos los lenguajes de programación (python incluido) ofrecen formas de evitarlo. Además es malo, porque entre otros motivos mientras más código escribimos, mayores son las probabilidades de que tengamos un error. Además, si encontramos un error , habría que buscar todos los lugares donde está presente ese bloque y corregirlo… (pudiendo tenerlo bien en unos, mal en otros, etc.).
Para eso existen los que se llaman funciones (que tampoco son como las funciones matemáticas, aunque este punto es distinto en otros lenguajes, tema que habrá que dejar para otro posteo). Eso que en programación imperativa se llaman funciones se llamaban antiguamente rutinas y también procedimientos. Son rutinas porque conforman un bloque de instrucciones que se repite cuando es necesario y de la misma forma. La idea de «función» viene porque (casi) siempre que usamos una de estas «rutinas» lo que queremos es calcular un resultado. En el caso del máximo común divisor es claro porque estamos computando una función (en sentido matemático) que le asigna un único número natural a todo par de números naturales.
Como dije, una función en python (y en general en cualquier lenguaje imperativo) es muy diferente a una función matemática. Primero, porque podría no «devolver» siempre el mismo resultado para un input. Esto puede parecer raro, pero supongamos que queremos modelar una moneda con peso. Una moneda con peso es una donde la probabilidad de salir cara es distinta de la de salir seca. Entonces, por ejemplo, podíamos definir una «función» (pseudofunción podríamos decir más correctamente quizá) que reciba el «peso» de cara y devuelva «cara» o «seca» de acuerdo a la probabilidad dada. Claramente esto no es una función en sentido matemático, pero tiene un input y un output.
Otro ejemplo es la función input que lo que hace es esperar a que el usuario escriba algo y lo guarda en una variable, mostrándole en la pantalla lo que se le haya pasado como argumento, es decir:
>>> x =input("Cuál es tu input? ")Cuál es tu input? No sé>>> x'No sé'
Acá está claro también que no es ninguna función en sentido matemático.
La misma «función» print nos interesa no por el valor que devuelve:
>>>print(print("Hola mundo"))Hola mundoNone
Acá vemos que print("hola mundo") devuelve None.
Lo que distingue a las funciones como mcd y las funciones como input o print es que cuando vemos mcd(54, 123) podemos reemplazar eso por el resultado (el valor de mcd aplicada a esos números) y el programa se va a comportar de la misma manera. Pero no podemos hacer eso con input ni con print (ni con otras funciones). Esta propiedad que tienen las funciones como mcd se llama transparencia referencial. Pero vamos a hablar de eso un poco más cuando introduzcamos el paradigma funcional.
Veamos entonces cómo hacemos para evitar el código repetido escribiendo en python la función mcd. La idea es que los números de los cuales queremos calcular el mcd sean «parametrizados» y el resto funcione igual. Para esto hacemos así:
def mcd(a, b): res = awhile a % res !=0or b % res !=0: res = res -1print(res)
Esto es algo mejor, ahora podemos «llamar» a la «función» mcd cada vez que querramos imprimir el máximo común divisor entre dos números pasándole como parámetros los números en cuestión. Sin embargo, hay algunos problemas ahí. En nuestro afán de sacar el código repetido, terminamos definiendo una función que hace demasiado: no sólo calcula el mcd si no que además lo imprime en la pantalla. Eso no es bueno porque, básicamente, uno podría querer calcular el número sin necesidad de imprimirlo en la pantalla, y en tal caso la función esta no serviría.
def mcd(a, b): res = awhile a % res !=0or b % res !=0: res = res -1return res
Ahora sí tenemos algo más parecido a una función que calcula lo que queremos.
Pero hay un problema de otra naturaleza: el programa si bien correcto es ineficiente. Hay varias formas de hacerlo mejor, y en la página de wikipedia pueden verse algunas. Ahora sólo vamos a ver el algoritmo de Euclides porque es el más simple. Y la idea es asi, si r es el resto de dividir a por b entonces el mcd entre a y b es el mismo que entre b y r. Por ende, en cada iteración en vez de probar el predecesor (el siguiente número para abajo) como hacíamos antes hasta llegar al mcd, usamos el resto r0 de dividir a por b luego el resto r1 de dividir a por r0 y así. Porque la propiedad se usa cada vez con cada r, es decir que el mcd entre a y b es el mismo que entre a y r0, que r1, que r2, … para todos los restos que obtengamos de esta forma. Como el resto siempre es estrictamente menor que el divisor en cada iteración nos vamos acercando. Y como el mcd siempre es el mismo nunca «nos pasamos» ya que si algún resto ri nos diera menor que el mcd, entonces no se cumpliría la propiedad entre a y ri − 1. Queda ver la prueba de que el mcd es el mismo, pero eso lo dejo como ejercicio. El programa queda entonces así:
def mcd(a, b)while b !=0: t = b b = a % b a = treturn a
Y acá b va tomando los valores r0, r1, r2, …, mcd.
Y esto nos deja con una pregunta, ya que el post se extendió bastante como para continuarlo en otro en lugar de prolongarlo más: ¿Cuál es la tarea del programador? ¿Es conocer las propiedades de los números y encontrar nuevas que puedan ser útiles? ¿Es hurgar en las propiedades que conocen los mátemáticos (u otros) para encontrar procedimientos que resuelvan cosas en lo posible rápido? ¿Es saber dónde ir a buscar los algoritmos par acopiarlos y pegarlos donde haga falta? ¿Es conocer el nombre de las funciones, modulos, librerías, framewors, etc., que ya resuelven lo que haya que hacer y simplemente escribirlo?