Las computadoras están diseñadas de fábrica para poder realizar las operaciones que se necesitan para hacer una calculadora simple, de ahí que puede ser buena idea que uno de los primero programas para alguien que quiere empezar sea una calculadora, ya que no es necesario implementar tantas otras cosas como en otros proyectos. Desde luego, pueden usarse librerías para no tener que implementar todo en tales casos, pero al principio puede dejarse para después el tema de las librerías.
Y cuando se me ocurrió este posteo lo primero que hice fue buscar en google para ver si no era algo demasiado hecho. Lo que me llamó la atención es que si bien hay varias páginas que muestran cómo hacer una calculadora, las que se trae como primero resultados muestran que nada cómo hacer una interfáz para que un usuario escriba dos números y una operación para después pedirle a la computadora el resultado y mostrarlo en la pantalla.
En el otro extremo hay una página que muestra lo siguiente código (en python):
print(eval(input()))
Ese ejemplo incluye una calculadora, pero también mucho más, porque la función eval lo que hace es justamente pasarle al intérprete de python lo que sea para que lo evalúe. Y si es una expresión artmética lo va a calcular, pero puede eveluar cualquier expresión de python. Eso puede implicar riesgos para la seguridad del sistema, asi que no es aconsejable tampoco… (imagínense pasarle a eval cosas como exec('import os; print(os.listdir(os.getenv("HOME")))') o peor, que borren archivos, etc.
La idea entonces es hacer algo que no es ni una cosa ni la otra, tratando en el camino de entender qué vamos haciendo, hasta cierto punto al menos. Un programa que recibe una expresión aritmética como «7 + 8 * 6» y devuelva como resultado el número que esa expresión denota. O sea, a diferencia del primer ejemplo podemos hacer más de una operación «por cuenta» y a diferencia del segundo sólo vamos a resolver operaciones ariméicas y no cualquier expresión de python.
La interfáz es bien simple: nuestro usuario va a llamar una función que vamos a llamar calcu y a pasarle una string donde esté la expresión, algo como calcu("21 * 24 / (4 + 3)"). Y si la expresión está mal formada directaente vamos a fallar de forma poco amigable (en otro posteo podemos hacer algo mejor en ese aspecto pero en este no vamos a mantener simples).
Las operaciones binarias a soportar son +, -, *, /, ^ y también vamos a poder usar numero negativos que empiecen con - unario (más adelanta más sobre esto). Las prioridade de agrupación son las habituales, o sea + tiene menos prioridad que *, etc., y usamos los préntesis si queremos un orden distinto al de la convención como (3+4)*5. Vamos a evaluar una sola expresión y no vamos a usar variables, cosa que también podríamos ver, quizá, después.
Pero qué es lo que vamos a considerar una expresión válida? Cómo definimos cuáles son las expresiones que están bien y las que no? Bueno quizá si uno de la nada quiere especificar esto puede ser bastante complicado dar con una respuesta (el lector podría intentar dar con alguna forma por su cuenta), pero por suerte es un problema ya resuelto y la solución se llama notación de Backus-Naur.
Puede leerse el artículo de wikipedia para entender mejor pero lo que necesitamos saber por ahora es que cuando usamos un := lo que está a la izquierda puede reemplararse por lo de la derecha y cualquier expresión que pued obtenerse así es válida, siempre que empiece del «símbolo distinguido». Vamos mejor a un ejemplo ya que la idea es simple aunque dificil de resumir en una línea. El ejemplo es justament nuestra gramática de expresiones aritméticas.
E := E + T
| E - T
| T
T := T * F
| T / F
| F
F := (E)
| Num
| -Num
Esta gramática es parecida (pero distinta) a la que está en esta página a la que el lector puede ir a ver por si le sirve para entender cómo se usa. Pero trato de explicar brevemente (ya que en realidad no es el tema de este posteo).
La idea es que una expresión pertenece a nuestra gramática siempre y cuando haya una forma de «generarla» partiendo del símbolo E y llegando a algo done de no haya más que +, -, *, /, (, ) y Num donde Num en realidad significa una número (si el lector sabe de regex, sería algo que matchee ([0-9]*[.])?[0-9]+ por ejemplo).
Cómo se genera una expresión en base a otra? Bueno, siempre podemos reemplaza cualquiera de los símbolos a la izquierda de := (el | es una manera abreviada de decir lo mismo) por lo que aparece a la derecha, ejemplo: E => E - T o (E) => (F). Nótese en el segundo ejemplo que (E) aparece a la derecha también, pero lo que nos importa es que como E := F entonces aplicamos esto a (E) y nos queda (F).
Es decir, usamos los símbolos E, T, F por un lado y los comunes +. -. *, ... etc. Num en realidad se refiere a cualquier número. Los E, T, F se llaman «no terminales» porque en sí mismos nunca están en una expresión, hay que derivarlos, del siguiente modo: para generar una expresión partimos del síbolo E (es nuestro símbolo distinguido) y aplicamos las reglas todas las veces que sea necesario hasta llegar a algo que no tenga más «no terminales». De E tenemos 3 opciones E + T, E - T y T. Y después tenemos que seguir, por ejemplo:
E -> E * T -> T * T -> F * T -> (E) * T -> (E + T) * T -> (T + T) * T ->...-> (Num + Num)
* Num
La definición de esta gramática es importante para el usuario porque una misma expresión puede estar bien o mal según qué gramática sea. No siempre los usuarios están al tanto de estas diferencias. Por ejemplo, si buscamos «calculadora» en google el mismo google nos da una calculadora en la cual no podemos escribir por ejemplo - -2. En python, por el contrario, - -2 es una expresión válida, a saber -(-2) que equivale a 2. Incluso podemos escribir --2 y es igual. Pero esto no ocurre así en todos los lenguajes. Por ejemplo, el shell de java interpreta esto como un error:
jshell> --2
| Error:
| unexpected type
| required: variable
| found: value
| --2
| ^
#
Algo similar ocurre con la calculadora bc:
bc 1.07.1
Copyright 1991-1994, 1997, 1998, 2000, 2004, 2006, 2008, 2012-2017 Free Software Foundation, Inc.
This is free software with ABSOLUTELY NO WARRANTY.
For details type `warranty'.
--2
(standard_in) 1: syntax error
En haskell es más particular, pues se ignora la expresión dado que -- es la forma de inicial un comentario…
En nuestro caso vamos a adotar la decisión de no admitir más de un - consecutivo para ivnertir el signo de un número (tal como especifica nuestra gramática): después de todo no hace falta. O sea hacemos como la calculadora del buscador. Y si el usuario quiere igual puede hacer -(-2).
Estas diferencias provienen de la ambigüedad de usar un mismo símbolo - para dos cosas: sumar, cambiar el signo. Y demás de que en realidad el usuario no escribe directamente en nuestra gramática. Él escribe caracteres, eso es lo que leemos, y tenemos que hacer una pimera traducción de los caracteres a nuestr a gramática. Es decir, nosotros leemos el símbolo - que por sí mismo no nos dice cuál de los dos significados tiene. Por suerte es facir saberlo por el contexto, an particular, por lo que hay antes. Observando nuestra gramática vemos que es una resta binaria sólo si viene inmediatamente después de una E y es el cambio unario de signo si empieza un F. Tenemos que mirar un poco más hasta ver qué símbolos terminales pueden estar en ambos contextos, y es fácil llegar a que la última parte de una E puede ser un Num o un ) y entonces si vemos un - después de alguno de estos dos sabemos que es un asuma. Y F tenemos después de *, / o (, con lo cual la ambugüedad se resuelve leyendo sólo lo último que se haya leído antes.
Vamos entonces a hacer dos pasadas: en la primera leemos los caracters de a uno y devolvemos una expresión válida en nuestra gramática donde cada elemento es un «símbolo terminal» de la misma, es decir, alguno de los operadores, paréntesis o un número. Después vamos a leer esta cadena resultante y hacer la cuenta.
Un último comentario. Dije ya que si la entrada no corresponde a la gramática no nos interesa dar un resultado útil. Por ejemplo «1 1» no tiene sentido así que no nos ocupamos de dar alguna respuesta en tales casos. Pero puede ocurrir que la entrada sea correcta desde el punto de vista sintáctico y así y todo no tenga sentido. Es el caso de entradas como «1 / 0». En ese caso se obtiene correctamente E -> T -> T / F -> F / F -> 1 / F -> 1 / 0. Pero matemáticamente no tiene sentido. Hacer una gramática que no acepte ese conjunto de entradas y sí el resto no valdría la pena. Lo que vamos a hacer es pasarle a python la cuenta y python nos va a tirar una excepción que vamos a dejar pasar.
Ahora sí, entonces, podemos pasar al algoritmo. En primer lugar, el traductor de caracteres a tokens. La idea es simplemente leer salteando los espacios. Si es una operación, entonces agregarla como token, si es el primer caracter de un número, leer todo el número y agregarlo. El único detalle a tener en cuenta es la ambigúedad de - que se maneja como se dice arriba. El resultado es una lista de string, cada elemento de la lista es un token (o un lexema) de nuestra gramática:
def read_number(s, i):
return next((k for k,e in enumerate(s[i+1:]) if e in " +-*/^()"), len(s[i:]) - 1) + i + 1
def read_expression(s):
tokens = []
last = "^"
i = 0
while i < len(s):
if s[i] == " ":
i = i + 1
pass
elif s[i] in "+*/^()" or (s[i] == "-" and last in "0123456789)"):
tokens.append(s[i])
last = s[i]
i = i + 1
else:
ix = read_number(s,i)
tokens.append(s[i:ix])
last = s[ix-1]
i = ix
return tokens
La segunda parte es un poco más complicada. Usamos dos pilas, una con las operaciones y otra con los «valores». Estos valores son o bien los número que vamos leyendo o aplicaciones parciales de la cuenta que queremos hacer. El tema es que para aplicar una operación necesitamos comparar la prioridad del operador con los que estén a ambos lados, y por eso los guardamos para hacer hasta que podemos comparar. Ahi entonces «reducimos» lo cual significa hacer la operación y su resultado se va guardandod en la pila de los valores:
priority = {
'+': 1,
'-': 1,
'*': 2,
'/': 2,
'^': 3,
'(': 0
}
opsfun = {
"+" : lambda x, y: x + y,
"-" : lambda x, y: x - y,
"*" : lambda x, y: x * y,
"/" : lambda x, y: x / y,
"^" : lambda x, y: x ** y
}
def reduceWhile(ops, vals, condition):
while ops and condition(ops[-1]):
vals[-1] = opsfun[ops.pop()](vals[-2], vals.pop())
def calcu(tokens):
ops, vals = [], []
expr = read_expression(tokens.strip())
for c in expr:
if (c == '('):
ops.append(c)
elif (c == ')'):
reduceWhile(ops, vals, lambda last: last != '(')
ops.pop()
elif c not in ["+", "-", "*", "/", "^"]:
vals.append(float(c))
else:
reduceWhile(ops, vals, lambda last: priority[c] <= priority[last])
ops.append(c)
reduceWhile(ops, vals, lambda x: True)
return vals[-1]
Y nuevamente, el posteo me quedó más largo de lo que imaginé en un principio y se extendería por ende demasiado si sigo. Por eso lo dejo acá y eventualmente lo continuaremos en comentario u otros posts (probablemente quiera hacer alguno con un enfoque completamente distinto, menos «machine-oriented» y más teórico usando las teorías sobre parsing.
El código de este post puede verse mejor en este gist.
Algunas veces tiene lugar la duda sobre qué lenguaje elegir. Por ejemplo, al empezar un nuevo proyecto. O incluso en una materia de la facultad pueden querer proponer un lenguaje para los trabajos prácticos. Ahora mismo, alguien que empieza a programar puede estar pensándolo.
Lo que está claro es que siempre es elegir un lenguaje para algo en particular, no es que un programador esté atado a uno. Y si bien algunos programadores ponen cosas como c++ developer en linkedin y algunas búsquedas también apuntan por ejemplo a un java developer, etc., lo cierto es que lo que tiene que aprender un programador no es un lenguaje de programación particular sino que es algo más amplio. Son ideas comunes a todos los lenguajes, ideas que se repiten, o hasta a veces aspectos del hardware por poner un ejemplo. En resumen, un lenguaje es una herramienta, no es ni el principio ni el fin de la programación.
No conozco programadores con alguna experiencia que programen únicamente en un único lenguaje. De hecho, Bjarne Stroutroup quien dedicó su carrera a un lenguaje, dijo queNadie debería llamarse a sí mismo un profesional si conoce sólo un lengauje y que 5 es un buen número de lenguajes para aprender razonablemente bien. Y termina proponiendo 5 entre C++ (obvio), Java, quizá Python, Ruby y JavaScript, C y C#.
Por otra parte, Larry Wall responde a la misma pregunta (de cuáles son los 5 lenguajes que recomienda aprender) agregando un dato no menor: eso va cambiando con el tiempo. Y pone por ejemplo que cuando empezó la respuesta hubiera sido Fortran, Cobol, Basic, Lisp y quizá APL. Pero que hoy en día (lo dijo en 2011) era probablemente más importante saber JavaScript. Menciona también Java (el Cobol del SXXI dice…, vean el video que está muy bien). A Haskell, a C y finalmente a Perl.
Para el lector que está empezando en este momento esto no es un problema, porque no es que tenga que tomar una decisión como quien elije una carrera. Se trata más bien de una especie de charla de sobremesa entre programadores. O sea, inevitablemente un programador termina conociendo al menos 5 lenguajes (qué tan bien depende de cuanto le guste su profesión o al menos ese aspecto) e inevitablemente va a verse involucrado en alguna conversación sobre cuál es más conveniente con colegas.
Además, así como a veces se elije, otras no, y hay que usar el que ya se eligió con anterioridad (probablemente esta sea la razón por la que ese usa tanto java …).
Y lo peor que puede hacer alguien es perder tiempo con este tipo de dudas.
Lo bueno es que (como dice Stroustroup) hay lenguajes que se parecen y aprender uno es también aprender otros. Así que acá vamos a optar por un camino distinto al de muchos libros o cursos introductorios de atarse a un lenguaje particular, y vamos a ver algunos, no uno solo, y vamos a tratar de entender eso que tienen en común que justamente hace que aprender uno implique aprender el otro. Eso no significa que si, por ejemplo, uno tiene mucha práctica con java despúes se pone a escribir javascript de memoria sin consultar nada en internet o los libros. Siempre que uno ve un lenguaje por primera vez se tiene que pasar algún tiempo mirando su sintaxis, sus librerías y cosas así. Y también es cierto que por más que uno tenga mucha experiencia con un lenguaje va a tener que estar buscando cosas en internet (incluso ya sabidas pero no recordadas con total exactitud) o incorporar los cambios que traen las nuevas versiones.
Dicho esto es obvio que no voy a hablar de todos los lenguajes que existen sino solo de un subcojunto bastante menor. Por ejemplo, es poco probable que hable de cobol acá. Pero la idea es hacer una introducción para quienes quieren empezar, y que sirva incluso para quienes vayan a usar lenguajes de los que acá ni aparecen ejemplos.
Así que pasemos a algunos comentarios generales.
Paradigmas de los lenguajes de programación
Esto de los paradigmas si bien se lo encuentra bastante no es un concepto formal y del todo claro. En algunos puntos hay matices. Pero hay aspectos que sí son claros. Y los lenguajes de programación (y sus usiarios!) a veces se caracterizan por estar más encuadrados a un paradigma. Además, creo que es justamente lo que los lenguajes buscan implementar de un paradigma una de las cosas hace que se parezcan tanto entre sí. Por ejemplo, en uno de los «paradigmas», llamado funcional existe la idea de funciones de alto orden que fue incorporada por muchos lenguajes de programación (en particular por todos los nuevos), incluso lenguajes que originalmente eran los abanderados de otro paradigma, como el de programación orientada a objetos. El punto al que voy es que una vez que uno entiende esa idea y qué tiene de bueno tener ese tipo de funciones y cómo usarlas, etc., después no cuesta nada ver los detalles de sintaxis para hacerlo en los lenguajes que lo permiten, como pueden ser C++, Kotlin, JavaScript, Python, etc. etc. O sea, aprender y estár cómodo usando funciones de alto orden es un herramienta en sí misma, que después se puede aprovechar con cualquier lenguaje comúnmente usado hoy por hoy.
Por otra parte este es un punto que también se puede dar en discusiones de sobremesa (y probablemente puedan ser más acaloradas que las de los lenguajes?). Qué paradigma usar o cuál es mejor? Yo voy a tratar de evitar ir directamente a esta cuestión porque suele basarse en opiniones. Y obvio que tengo mis opiniones al respecto, como todo el mundo, pero mi idea es ir exponiéndolas cuando sea necesario y a medida que le puedan llegar a servir a quien esté aprendiendo.
Pero me parece importante hacer notar un punto central en todos estos debates. A saber, que todo esto se da de esta manera porque programar no es una actividad solitaria. Uno puede programar solo y es muy divertido (tal vez sea más divertido…) pero en la vida real, por ejemplo en la industria, se trabaja en un equipo donde pueden haber distintos puntos de vista e inevitablemente existirán veces donde unos se impongan sobre otros (este punto es particularmente de interés). Esto puede ocurrir en cosas muy claras como la elección de un lenguaje de programación para hacer algo. O en una code review puede haber una discrepancia que tenga que ver con si hacer algo con un estilo funcional o no, por ejemplo. O mismo dentro de un paradigma se dan diferencias: tal tarea es responsabilidad de qué clase? usamos o no tal patrón de diseño? etc.
Quizá alguna vez alquien interprete la historia de la programación como la dialéctica de la lucha entre paradigmas. Pero en cualquier caso no ese el tema de este post.
Ya iremos viendo qué son esas cosas que mencioné sin introducir como funciones de alto orden, clases, patrón de diseño, el punto era ilustrar que son cosas del día a día, además de discusiones a veces improductivas. Y que en ocasiones se trata más de una habilidad social puesta en juego en una argumentación para adoptar un enfoque que uno prefiere o no dentro de un equipo. Y que conocer todo lo que está relacionado a los paradigmas sirve para, por ejemplo, no perder tiempo inventando lo que ya se hizo o intentando enfoques que se demostraron mejorables, aunque también para poder comunicarse mejor en esas discusiones para entender mejor y que a uno lo entiendan mejor. Además de que muchas de estas cosas están harcodeadas y conocerlas facilita mucho la comprensión del código que uno tiene que leer al programar. Y me permito una nota sobre esto: reinventar la rueda, acción que es tan menospreciada, puede ser el origen de un punto de vista creativo y que permita expandir los horizontes, pregúntenle a Frege si no.
Todos los lenguajes de programación tienen en común el permitirle a alguien (o sea al programador) que le diga a la computadora lo que tiene que hacer. Es decir, darle algo para hacer. Esto es común a todos. Pero después cuando vemos cómo se hace esto las cosas difieren.
Paradigma imperativo
Una subrutina puede verse como una extensión del lenguaje máquina de la computadora.
– Donald Knuth
Al principio de la computación, las instrucciones eran las que traía la maquina (el hardware) de fábrica, el set de instrucciones del que hablamos en otro post. Hoy ya no es así, (casi?) nadie programa escribiendo lenguaje máquina ni assembler. Por qué cambió esto? Bueno, porque es mucho más fácil, eficiente, seguro, y probablemente unos cuantos etcéteras, hacerlo con abstracciones más modernas como las que se usan hoy. Por qué no se hardcodean esas abstracciones? Bueno, esa pregunta habría que hacérsela a los fabricantes de hardware. Pero lo interesante es ¿Qué nos permite hacerlo de esta otra manera? Y la respuesta es: el software. Entre la maquina procesando instrucciones de su instruction set y las expresiones que escribe un programador hay software en el medio que se encarga de traducir de un lenguaje a otro. Ese software es desarrollado y mantenido por programadores, pero probablemente la mayoría de los programadores se dedican al menos el día de hoy a usar esos programas y escribir aplicaciones con los lenguajes de más «alto nivel», o sea, los que se alejan más de la máquina porque tienen abstracciones en el medio implementadas en software por otros programadores.
Una de estas abstracciones (bien básica) es la de variable. En computación y sobre todo en el paradigma imperativo (en otros paradigmas es diferente), una variable es algo diferente a lo que es en matemática. En matemática las variables son incógnitas, o bien conjuntos con incógnitas. En una ecuación como x = x2 simplemente denota un conjunto de números que reemplazándolos por la x hacen que la expresión tenga sentido. En este caso, que usando un poquito de álgebra nos dá que es equivalente a 0 = x( − 1 + x) vemos que la ecuación vale si x ∈ {0, 1}.
En computación imperativa, es una cosa totalmente diferente. Una variable no es más que el nombre de un lugar donde guardo algo. Así de simple. Para ver esto podemos abrir un intérprete interactivo de python, Así, por ejemplo, podemos escribir:
>>> x =2
Y con eso no estamos denotando el número 2 o el conjunto que contiene al número dos (ni tampoco eso es equivalente a 0 = 2 − x. Cuando escribimos eso en python estamos diciéndole a la computadora: guardame en este lugar, x, el
número 2.
También podemos escribir, en python:
>>> x = x * x
Esto tampoco tiene nada que ver con una ecuación matemática. Le estamos diciendo a la computadora que eleve el valor guardado en x al cuadrado y que al resultado lo guarde en x, o sea en el lugar de la memoria que llamamos x. Esto tiene sentido porque la parte de la derecha ocurre primero y después se guarda el resultado de la cuenta en x, pisando el valor que había antes, que era un 2 porque lo habíamos puesto ahí.
Dije que «la parte de la derecha ocurre primero». Esa es una forma de hablar, mucho mejor es decir que primero se ejecuta la expresión de la derecha y su resultado se guarda en la variable que hay a la izquierda.
Es fácil ver esto. Si uno quiere usar la variable sin antes haberle «hecho saber» a la computadora que ese nombre era el de una variable, la computadora nos va «tirar un error». Y digo tirar un error en vez de devolver un error porque hubiera devuelto algo si nosotros pedíamos eso que devolvía, pero tratándose de un error es algo distinto: la ejecución se interrumpe y se avisa que no se pudo continuar con lo que se estaba.
Así, si no hubiéramos puesto algo en ese variable la cosa no hubiera funcionado:
>>> y = y * y
El intérprete de python nos va a decir: NameError: name 'y' is not defined. Es decir: nunca me dijiste que haga lugar en la memoria para un objeto con
ese nombre.
El signo =, entonces, se usa en python para guardar objetos en la memoria. Para la igualdad se usa este otro: ==, o sea dos símbolos de igual seguidos. Tal vez la elección de estas convenciones no haya sido la mejor, y puede ocurrir que por un error de tipeo uno escriba = en vez de == y vice versa y después pierda mucho tiempo con un error inentendible en un programa. Pero esta es la elección de muchos lenguajes y resulta ser uno de esas cosas (trivial en este caso) que son comunes a muchos lenguajes.
Pero igualmente, usando == estamos en la misma. Si escribimos únicamente
>>> y == y * y
tenemos un error de nombre y si escribimos
>>> y =2>>> y == y * y
Simplemente vamos estar escribiendo 2 es igual a 2 + 2, y lo que vamos a obtener es que es falso. Cuando lee y == y * y la maquina empieza preguntando ¿qué es y? y es 2, porque guardamos eso arriba. O sea que queda 2 == 2 * 2. Después evalúa2 * 2. Las computadoras son muy buenas para eso, es 4. Finalmente evalúa 2 == 4, algo que también sabe hacer: eso es falso, 2 no es 4. Entonces termina diciendo eso mismo:
>>> x =2>>> x == x * xFalse
Acá no estamos volviendo a escribir en x después de haber escrito 2 porque == no escribe, el que escribe es =. La operación que se realiza cuando se lee ese símbolo se llama asignación y consiste entonces en leer lo que hay a la derecha de =, evaluarlo, y finalmente guardarlo en la variable que hay a la izquierda, que como dijimos es el nombre que le pusimos a una parte de la memoria para acordarnos y poder pedirlo más tarde para usarlo. Esta claro entonces que no da lo mismo qué va a la izquierda y que a la derecha del =, es decir x = x * x no es lo mismo que x * x = x. En efecto:
>>> x * x = x x * x = x^SyntaxError: cannot assign to operator
El intérprete acá nos dice que no puede «asignar a un operador». Se refiere al operador * con el que multiplicamos, ya que no es el nombre de ningún lugar en la memoria. Cuando algo puede estar a la izquierda de =, como la variable x, se dice que es un lvalue (l por left). Cuando algo puede estar a la derecha se dice que es un rvalue (r por right).
Pero entonces volviendo a nuestro problema inicial ¿hay manera de que la computadora nos averigüe lo que la fórmula matemática estaba expresando, o sea la raíces de la ecuación x = x2?
Bueno en este caso podemos por ejemplo usar «la resolvente de la cuadrática» que vemos en la secundaria
y esas son todas operaciones que la computadora «ya sabe» hacer. Pero es importante notar que existe una gran diferencia entre la expresión matemática, que directamente está denotando el conjunto de soluciones, independientemente de si alguien sabe o no cuáles son, y la expresión como programa, que codifica instrucciones para que ejecute una máquina. El programa tiene que encontrar la forma de encontrar los resultados, no le basta con denotarlos (ni simplemente decir que existen). Y obviamente es el programador el que tiene que buscar cómo.
Para eso tiene que usar las operaciones que provee. Veamos el siguiente programa que calcula el máximo común divisor entre 72 y 54 y el de 123 y 42. Elijo un ejemplo que puede parecer medio «matemático» para empezar pero no porque la programación sea frecuentemente resolver este tipo de problemas (ya que lo común es usar soluciones ya escritas para estos casos), sino porque para empezar al haber pocos conceptos que se asumen disponibles para la programación no queda más remedio de usar los más básico: números y operaciones sobre números.
En ese bloque, además del operador de asignación que ya mencionamos, se usa el % (o módulo), != («es distinto que»), or (u o) y la resta -. Por último se usa el while.
Lo primero que hacemos es guardar el número 54 en mcd. Esto es porque el mcd entre 54 y 72 necesariamente tiene que ser menor o igual que el mínimo de ambos, o sea que 54. Después usamos un loop, llamado while. while sirve para repetir un bloque de código siempre que una determinada condición no se cumpla. En este caso la condición es 54 % mcd != 0 or 72 % mcd != 0. El bloque en cuestión, que en este caso es mcd = mcd - 1 se va a repetir siempre que el valor ne mcd no divida a 54 o a 72. O sea, va a frenar si (únicamente si) divide tanto a uno como al otro. Esta es la condición que esperamos que cumpla porque es la que cumplen todos los divisores comunes a ambos números. Cada vez que la condición no se cumple, probamos con el número entero inmediatamente más chico. Esto lo hacemos «decrementando» (lo contrario de incrementar) el valor que hay en mcd.
¿Cómo sabemos que este programa funciona correctamente? Un programa puede ser incorrecto de al menos tres maneras en un caso como este. Puede computar un número distinto al que queríamos, o puede «colgarse» y no terminar nunca. Esto en particular es un riesgo cierto cada vez que usamos while. Y también puede interrumpirse debido a algún error.
En este caso sabemos que el programa no se va a colgar por el siguiente motivo. mcd empieza siendo 54 y va bajando de a uno: 54, 53, 52, … Si este programa se colgara sería porque mcd bajaría indefinidamente sin que se cumpliera la condición. Pero esto no puede ser, porque si bajara indefinidamente eventualmente valdría 1, y tanto 54 % 1 como 72 % 1 dan 0, y en tal caso se saldría del while. Esto significa, de paso, que mcd nunca va a llegar a 0. Esto es importante, porque si llegara a 0, entonces se produciría un error:
>>> mcd =0>>>54% mcdTraceback (most recent call last): File "<stdin>", line 1, in<module>ZeroDivisionError: integer division or modulo by zero
Este error haría que el programa se interrumpa y termine pero sin calcular ningún valor ni nada. Pero como dijimos, mcd no llega a 0 y en cambio sí está definida para todos los valores mayores o igual a 1.
Por otra parte, sabemos que el máximo común divisor tiene que ser menor o igual que 54, porque ningún número mayor a 54 puede ser divisor de 54. Y como vamos de a uno desde 54 hasta 1, el primero que encuentre va a ser el mayor de todos.
Así, el programa es «correcto», en el sentido en que computa el número buscado. Sin embargo amerita algunos comentarios.
En primer lugar vemos lo que se llama código repetido. Casi calcadas tenemos las mismas 4 líneas. Esto es algo malo y mejorable. Es mejorable porque todos los lenguajes de programación (python incluido) ofrecen formas de evitarlo. Además es malo, porque entre otros motivos mientras más código escribimos, mayores son las probabilidades de que tengamos un error. Además, si encontramos un error , habría que buscar todos los lugares donde está presente ese bloque y corregirlo… (pudiendo tenerlo bien en unos, mal en otros, etc.).
Para eso existen los que se llaman funciones (que tampoco son como las funciones matemáticas, aunque este punto es distinto en otros lenguajes, tema que habrá que dejar para otro posteo). Eso que en programación imperativa se llaman funciones se llamaban antiguamente rutinas y también procedimientos. Son rutinas porque conforman un bloque de instrucciones que se repite cuando es necesario y de la misma forma. La idea de «función» viene porque (casi) siempre que usamos una de estas «rutinas» lo que queremos es calcular un resultado. En el caso del máximo común divisor es claro porque estamos computando una función (en sentido matemático) que le asigna un único número natural a todo par de números naturales.
Como dije, una función en python (y en general en cualquier lenguaje imperativo) es muy diferente a una función matemática. Primero, porque podría no «devolver» siempre el mismo resultado para un input. Esto puede parecer raro, pero supongamos que queremos modelar una moneda con peso. Una moneda con peso es una donde la probabilidad de salir cara es distinta de la de salir seca. Entonces, por ejemplo, podíamos definir una «función» (pseudofunción podríamos decir más correctamente quizá) que reciba el «peso» de cara y devuelva «cara» o «seca» de acuerdo a la probabilidad dada. Claramente esto no es una función en sentido matemático, pero tiene un input y un output.
Otro ejemplo es la función input que lo que hace es esperar a que el usuario escriba algo y lo guarda en una variable, mostrándole en la pantalla lo que se le haya pasado como argumento, es decir:
>>> x =input("Cuál es tu input? ")Cuál es tu input? No sé>>> x'No sé'
Acá está claro también que no es ninguna función en sentido matemático.
La misma «función» print nos interesa no por el valor que devuelve:
>>>print(print("Hola mundo"))Hola mundoNone
Acá vemos que print("hola mundo") devuelve None.
Lo que distingue a las funciones como mcd y las funciones como input o print es que cuando vemos mcd(54, 123) podemos reemplazar eso por el resultado (el valor de mcd aplicada a esos números) y el programa se va a comportar de la misma manera. Pero no podemos hacer eso con input ni con print (ni con otras funciones). Esta propiedad que tienen las funciones como mcd se llama transparencia referencial. Pero vamos a hablar de eso un poco más cuando introduzcamos el paradigma funcional.
Veamos entonces cómo hacemos para evitar el código repetido escribiendo en python la función mcd. La idea es que los números de los cuales queremos calcular el mcd sean «parametrizados» y el resto funcione igual. Para esto hacemos así:
def mcd(a, b): res = awhile a % res !=0or b % res !=0: res = res -1print(res)
Esto es algo mejor, ahora podemos «llamar» a la «función» mcd cada vez que querramos imprimir el máximo común divisor entre dos números pasándole como parámetros los números en cuestión. Sin embargo, hay algunos problemas ahí. En nuestro afán de sacar el código repetido, terminamos definiendo una función que hace demasiado: no sólo calcula el mcd si no que además lo imprime en la pantalla. Eso no es bueno porque, básicamente, uno podría querer calcular el número sin necesidad de imprimirlo en la pantalla, y en tal caso la función esta no serviría.
def mcd(a, b): res = awhile a % res !=0or b % res !=0: res = res -1return res
Ahora sí tenemos algo más parecido a una función que calcula lo que queremos.
Pero hay un problema de otra naturaleza: el programa si bien correcto es ineficiente. Hay varias formas de hacerlo mejor, y en la página de wikipedia pueden verse algunas. Ahora sólo vamos a ver el algoritmo de Euclides porque es el más simple. Y la idea es asi, si r es el resto de dividir a por b entonces el mcd entre a y b es el mismo que entre b y r. Por ende, en cada iteración en vez de probar el predecesor (el siguiente número para abajo) como hacíamos antes hasta llegar al mcd, usamos el resto r0 de dividir a por b luego el resto r1 de dividir a por r0 y así. Porque la propiedad se usa cada vez con cada r, es decir que el mcd entre a y b es el mismo que entre a y r0, que r1, que r2, … para todos los restos que obtengamos de esta forma. Como el resto siempre es estrictamente menor que el divisor en cada iteración nos vamos acercando. Y como el mcd siempre es el mismo nunca «nos pasamos» ya que si algún resto ri nos diera menor que el mcd, entonces no se cumpliría la propiedad entre a y ri − 1. Queda ver la prueba de que el mcd es el mismo, pero eso lo dejo como ejercicio. El programa queda entonces así:
def mcd(a, b)while b !=0: t = b b = a % b a = treturn a
Y acá b va tomando los valores r0, r1, r2, …, mcd.
Y esto nos deja con una pregunta, ya que el post se extendió bastante como para continuarlo en otro en lugar de prolongarlo más: ¿Cuál es la tarea del programador? ¿Es conocer las propiedades de los números y encontrar nuevas que puedan ser útiles? ¿Es hurgar en las propiedades que conocen los mátemáticos (u otros) para encontrar procedimientos que resuelvan cosas en lo posible rápido? ¿Es saber dónde ir a buscar los algoritmos par acopiarlos y pegarlos donde haga falta? ¿Es conocer el nombre de las funciones, modulos, librerías, framewors, etc., que ya resuelven lo que haya que hacer y simplemente escribirlo?
Seguimos con el plan mencionado anteriormente, empezando por el sistema operativo, y algunas aplicaciones. Quizá el lector ya use algún sistema operativo en particular, o quizá esté pensando en cuál elegir. En lo que respecta a este tutorial, al menos cualquiera de las tres opciones que son más populares hoy en día son válidas. Sólo haré algunos comentarios.
El sistema operativo tiene dos extremos. Por un lado se vincula con la máquina propiamente dicha, es el que controla en realidad las instrucciones que ésta va ejecutando. Y también maneja todos los “dispositivos” que son necesarios, como por ejemplo el disco rígido (podría quizá discutirse si los drivers -que hay que instalar para que funcione, por ejemplo, la “placa de video”- es o no parte del sistema operativo, pero no me parece que tenga sentido discutir eso ahora).
Por otra parte, se vincula con los programas que están corriendo en la computadora. Estos programas (después de todo son tan programas como el sistema operativo mismo) no acceden directamente al uso de los recursos de la máquina, sino a través del sistema operativo.
Por ejemplo, una aplicación suele usar abstracciones como los “archivos” (files) para leer o escribir en el disco. No se ocupa de los detalles de “bajo nivel” que hacen tan complicado programar esos drivers. El sistema operativo ofrece una interfaz a las aplicaciones para poder usar el disco de una forma más fácil y general (porque la misma interfaz es la que se usa para por ejemplo todo tipo de disco, independientemente del modelo, si es de estado sólido, etc.). Más fácil porque bueno, es decididamente más fácil decirle al sistema:
Abri el archivo f
Leé el contenido de f y copialo a la memoria m
Cerrá el archivo
que todo lo que hay que hacer para que efectivamente esto pase manipulando el disco con sus propias instrucciones. Y más general porque la misma interfaz es la que se usa para por ejemplo todo tipo de disco, independientemente del modelo, la marca, si es de estado sólido, etc.
Esta idea de interfaz es importante tenerla en mente porque está presente todo el tiempo. El programador no está únicamente averiguando cómo es una interfaz para poder usar algo. También, al programar, está ofreciendo una interfaz a alguien más (no importa qué sea lo que programe). Ofrecer un buena interfaz es parte de su trabajo.
Además de ofrecer una interfaz a las aplicaciones, el sistema operativo cumple una tarea de administración. Decide si un programa puede ejecutarse, o si no, si puede acceder a cierta parte de la memoria, etc. Por ejemplo, si le pido demasiada memoria, el sistema operativo en algún momento me dice que no y se encarga de tirar abajo la ejecución en curso.
El lector se preguntará ¿cómo? Si mi programa (una vez compilado) está hecho de instrucciones de la máquina, y la máquina ejecuta estas instrucciones, no tiene el control y le puede decir al sistema operativo que espere, por ejemplo? Es una muy buena pregunta. Lo que ocurre hoy por hoy (porque no era así hace 70 años) es que el programa en cuestión no tiene el control real de la máquina. En cambio, el sistema “le hace creer” que tiene el control, pero supervisa las instrucciones (no le permite leer cualquier parte de la memoria ni ejecutar determinadas instrucciones, esto con ayuda del hardware mismo) y, además, los pone a ejecutar y los pone en espera permanentemente.
En cualquier momento hay muchos programas corriendo “al mismo tiempo”, lo que significa que el sistema operativo les deja usar, sucesivamente a cada uno, un rato el procesador (y si tiene muchos procesadores sí pueden correr al mismo tiempo uno por cada procesador, claro).
Máquina, sistema operativo, aplicaciones, usuario.
Pero todo esto es tal vez todavía demasiado “bajo nivel” para lo que necesitamos todavía. A menos que nuestra aplicación (es decir, el programa que estamos desarrollando) se encargue de hacer cosas con archivos, es muy raro que usemos directamente la interfaz del sistema operativo. Y ahora estamos considerando al programador como mero usuario de sistema operativo (no todavía como programador de una aplicación que use su interfaz).
El usuario de sistema operativo está separado del mismo, entonces, por las aplicaciones. Son las aplicaciones las utilizan la interfaz que ofrece el sistema operativo, y al mismo tiempo tienen una interfaz de cara al usuario.
Es por esto que lo que le resulta familiar a un usuario de un sistema operativo son las aplicaciones que éste ofrece para usarlo. Por ejemplo la interfáz gráfica (como Aqua) o la línea de comandos.
La línea de comandos es un programa que, como dice su nombre, recibe lineas de “texto” que ejecuta a medida que las va leyendo. Los sistemas operativos tienen en general una línea de comandos para interactuar con el usuario que se llama shell. Esta idea se usa no sólo para manejar un sistema operativo. Por ejemplo, algo que es bastante útil para alguien que quiere dar sus primeros pasos con un lenguaje de programación es usar una interfaz de comandos interactiva en la cual se puedan escribir expresiones del lenguaje que se van ejecutando una por una. Hay disponibles entornos de este tipo para muchos lenguajes, incluyendo Haskell, Python, Java, etc., etc.
Pero en este momento vamos a ver algunos aspectos de Bash, que es un shell de unix, y es el que suele usarse en linux y también en mac.
Bash
Bash es un intérprete de comandos y un lenguaje de programación. Y, si bien es el primer lenguaje que vamos a ver acá, no es que vayamos a programar mucho con él. Simplemente es el medio más simple para lanzar otros programas, incluyendo los que hagamos nosotros, y manejar el sistema operativo en general.
Como dije, en linux es el shell por defecto. En mac ahora hay uno (muy parecido) que se llama zsh. Son bastante indistinguibles para las tareas más comunes. Linux y mac, desde el punto de vista del shell y con respecto a los programas típicos usados para programar son bastante parecidos (sacando Xcode), y windows es el que más difiere. En épocas en las que yo tenía que usar windows solía usar cygwin para tener un shell parecido, pero igual difería en algunos detalles. Hoy por hoy windows ya ofrece un “subsistema” linux así que también está disponible ahí. Otras opciones, dentro de windows, son usar su vieja consola (que es bastante fulera) o el Power shell, pero no vamos a ver eso al menos ahora.
Volviendo a bash, para abrirlo hay que abrir el programa que se llama terminal (tanto en linux como en mac se llaman así aunque hay otros con otro nombre). Esto nos va a abrir una ventana donde se va a leer algo similar a
pg@ubu:~$
(En mac veríamos algo así en realidad: → ~). Hay 6 partes en esa línea. pg es el nombre de usuario (que elegí al instalar el sistema). @ simplemente separa el nombre de usuario, a la izquierda, del nombre de la computadora (que también elegí al instalar). Los dos puntos (colon en inglés) separan eso de la parte siguiente: ~. Ese símbolo representa un directorio (una “carpeta”) en el sistema de archivos, llamado home, y es el que tiene asignado el usuario que está “loggueado” en la terminal, en este caso pg, o sea, yo.
Ese símbolo nos lleva a una aspecto central de bash. Si escribo ese símbolo y luego enter ocurre esto:
pg@ubu:~$ ~
bash: /home/pg/: Is a directory
Ese mensaje es un mensaje de error, un tipo de mensaje que es quizá lo que más lee cualquier programador en su día a día. Esos mensajes nos sirven para justamente ver qué escribimos mal. Sin esos mensajes todo sería mucho más difícil, o mejor dicho, los errores que no generan un mensaje son los más complicados. Claro que al principio puede no ser claro, pero eso es cuando uno todavía no leyó mucho.
El mensaje, entonces, se interpreta así. Primero dice bash:. Eso está diciendo de quien es el mensaje. Puede parecer una obviedad que si escribo un comando mal en la terminal de bash, entonces quien encuentra el error y lo muestra sea bash. Pero en realidad no siempre es obvio, porque uno en los comandos de bash la mayor parte del tiempo lo que hace es en realidad invocar otros programas y muchas veces son esos programas los que “tiran” el error. Después dice el path de mi home. Eso es porque es lo que recibió por parámetro: bash le pasó eso en lugar de ~ (por los motivos que ahora vamos a ver). Y finalmente cuál es el problema: “`/home/pg/ es un directorio, ya sé, pero qué querés que haga?” dice bash.
Otro ejemlo:
pg@ubu:~$ ls ""
ls: cannot access '': No such file or directory
Acá, por ejemplo, es ls quien tira el error. ¿Por qué? Por que lo invocamos en la línea que escribimos. Al programa ls, que sirve para listar el contenido del un directorio, le pasamos como argumento dos comillas doble, o sea "". Y nos dice que no puede acceder (tiene que acceder para poder mostrarnos su contenido) porque no existe.
Elegí este ejemplo porque si ponía alguno random corría el riesgo de que al correrlo en otra máquina el directorio existiera pero este sé que no existe, veamos:
pg@ubu:~$ mkdir ""
mkdir: cannot create directory ‘’: No such file or directory
Como indica ahora el programa mkdir, no se puede crear un directorio con ese nombre. Pero quizá al lector le llamó la atención que, mientras que yo usé comillas dobles, mkdir y ls usaron comillas simples. ¿Son sinónimos? No, no lo son. Sucede algo que está relacionado con lo del símbolo ~ que mencioné arriba y ahora voy a explicar.
El interprete de bash lo que hace es, cuando recibe una línea, es decir, cada vez que el usuario apreta enter, expande partes de la línea. Qué quiere decir? que reemplaza esa parte (no todas las partes si no algunas siguiendo ciertas reglas) por algo predeterminado. Así, "" es reemplazado por la “cadena vacía”. ~ es reemplazado por el directorio home del usuario que está logueado, como dije. Otras partes, como ls, quedan tan cual.
Pero entonces, no se puede escribir esos símbolos que se expanden porque siempre van a ser reemplazados? Se puede, se usa otro símbolo para eso: \. La barra invertida sirve para “escapar” los caracteres, poniéndola justo atrás. De echo podemos crear un directorio que que llame, literalmente "", siempre que escapemos las comillas, así:
$ mkdir funciones-que-funcionan
$ cd funciones-que-funcionan
$ mkdir \"\"
$ ls
'""'/
Qué hicimos acá? Creamos un directorio llamado funciones-que-funcionan para no ensuciar mi direcotrio home. Luego, cambiamos nuestra posición a ese directorio (para eso es el comando cd). Ahí creamos el directorio "", escapando las comillas para que no sean “expandidas”, o sea escribiendo \"\". El directorio se creó (no se generó ningún mensage de error) y de hecho los vemos usando el comando ls. Pero el output de ese comando no muestra \"\", sino '""'. Esa es otra forma de “escapar” las comilas. En realidad no se están escapando ahí si no que, como están metidas adentro de unas comillas simples, se toman literalmente, se dice que están citados, quoted. Ahora vamos a comprobar que, al menos para bash, '’ y " no son lo mismo:
$ mkdir \'\'
$ ls
'""' "''"
Pueden verse los los directorios, "" y '', (el primero quoteado con ' y el segundo con "). Podemos borrarlos, Por ejemplo:
$ rm -r '""'
En esta línea usamos el programa rm para borrar el directorio que creamos, pero en el medio agregamos -r. En la terminología eso se llama option y es es leída por el programa al que se la está pasando bash. Es decir rm -r implica pasarle -r como opción a rm pero si escribimos ls -r le estamos pasando esa opción a otro programa, ls. Y cada uno lo interpreta de una manera distinta. Para rm significa “borrá recursivamente directorios” lo cual significa, borrar primero el contenido y después el directorio en sí (cuidando de, al borrar el contenido, si se borra algún directorio, también sea recursivamente, borrando recursivamente el contenido y después él, más adelante vamos a hablar más de la recursividad). Pero para ls significa otra cosa completamente distinta, a saber, “mostrá el contenido en forma invertida” (reverse order). Es decir, lo que viene después del nombre del programa es responsabilidad del programa interpretarlo (después de la expansión que hace bash de los símbolos que dijimos antes).
Si quisiéramos listar recursivamente el contenido tendríamos que usar la opción -R y no -r.
Pero a todo esto, no nos desviamos de tema y en vez de hablar de bash terminamos hablando de otros programas? Bueno, en parte, porque la idea no es profundizar mucho en bash como lenguaje sino como una herramienta que nos va a servir para usar el sistema operativo para programar, Igual hay algo que es bueno, creo, conocer desde ahora.
Los programas, como vimos, reciben argumentos (o parámetros, en esto contexto se usan muchas veces como sinónimos, aunque en otros se diferencian). Algunos argumentos son opciones. Y entre las opciones hay las que son “cortas” (short options) y empiezan con un guión y son seguidas por una letra, como -r o -R. Podemos usar más de una opción al mismo tiempo, como en ls -r -R. Esto es lo mismo que ls -rR. Es decir, las opciones cortas pueden ir pegadas, encabezadas por un mismo guión, o pueden tener cada una su guión.
Después estás las opciones “largas” (long options) que empiezan con dos guiones y le sigue ya no una letra sino una palabra. Por ejemplo ls -r es lo mismo que ls --reverse y ls -Rls --recursive. ls -rR es lo mismo que ls --reverse --recursive. Dos guiones solos, -- tienen un significado distinto, justamente, significa que a la izquierda está la última ‘opción’ que el usuario le quiere pasar, y que a la derecha lo que hay (si hay algo) son parámetro pero no opciones, non-option arguments. Esto sirve por ejemplo si quiero que el programa acepte un argumento que empieza con un guión pero no es una opción.
En cuanto a las opciones cortas y largas ¿Para qué tenemos dos formas de hacer lo mismo? Bueno, supongo que por un lado la opción corta es más fácil de escribir y por ende más cómoda cuando ya la sabemos de memoria y la usamos mucho. Pero el mismo tiempo es más difícil de memorizar, y entonces la versión larga puede ser mas mnemónica.
Pero también es cierto que dado que las opciones cortas son una sola letra hay un límite en la cantidad que un programa puede ofrecer al usuario, porque no puede usar la misma más de una vez. En cambio, las opciones largas ya dan un universo de posibles opciones verdaderamente grande. Un ejemplo de un programa que tiene muchas opciones largas (sin su versión corta) es gpg.
Los programas tiene en general la opción --help (que a veces coincide con -h pero a veces, como en ls, no) que imprime una ayuda para el usuario (ya que es imposible acordarse de memoria las interfaces de todos los programas, con suerte la parte que usamos de los programas que más usamos).
Por ejemplo (pongo este ejemplo porque es bastante más corto de lo que es un man page en general):
$ mkdir --help
Usage: mkdir [OPTION]... DIRECTORY...
Create the DIRECTORY(ies), if they do not already exist.
Mandatory arguments to long options are mandatory for short options too.
-m, --mode=MODE set file mode (as in chmod), not a=rwx - umask
-p, --parents no error if existing, make parent directories as needed
-v, --verbose print a message for each created directory
-Z set SELinux security context of each created directory
to the default type
--context[=CTX] like -Z, or if CTX is specified then set the SELinux
or SMACK security context to CTX
--help display this help and exit
--version output version information and exit
GNU coreutils online help: <https://www.gnu.org/software/coreutils/>
Full documentation <https://www.gnu.org/software/coreutils/mkdir>
or available locally via: info '(coreutils) mkdir invocation'
Ahí aparecen las opciones y una breve descripción de qué hace cada una. Pero si queremos una descripción más desarrollada tenemos otro programa: man. man, como su man page lo indica, es una interfaz a los manuales de referencia del sistema. Es decir usamos man PROGRAMA para ver el manual del programa PROGRAMA. También hay un man para bash, que tiene, al menos la versión que estoy usando version 5.1.8(1)-release (x86_64-pc-linux-gnu) 3577 líneas.
Para saber esto usé otro comando wc (supongo que por word count) que muestra la cantidad de líneas, palabras y caracteres de un archivo.
Para usar wc podemos “pasarle” el archivo como parámetro, como venimos haciendo con los otros comandos. Pero también (y esto ocurre también con muchos otros programas) acepta su entrada por “entrada estándar” (standard input). Qué es esto? Bueno, es un concepto del sistema operativo que permite a un programa cualquiera (ya sea wc o uno que hagamos nosotros, etc.) leer texto (un stream en realidad) de un lugar particular que recibe ese nombre, standard input que se suele abreviar como stdin. Este stdin funciona como cualquier archivo (desde el punto de vista del programa), pero no nos vamos a meter muy en detalle en eso ahora. Lo que importa por el momento es que existe una entrada estándar (stdin) y también una salida estándar (stdout), y que desde el punto de vista de shell, stdout es simplemente el output que vemos impreso en la pantalla. Es decir que cuando escribimos man bash, los que vemos es el stdout de man para el parámetro bash. Y nosotros podemos redirigir ese stream, o sea, eso que sale por stdout al stdin de otro programa. Para hacer esto, es decir, para mandar la salida de un programa a la entrada de otro (el otro programa tiene que aceptar stdin para que esto funcione obviamente) usamos el símbolo | llamado pipe, del siguiente modo:
$ man bash | wc
3577 49766 338778
Este comando hace que la salida de man bash vaya a la entrada de wc (que está preparado para eso digamos) y wc como dijimos nos muestra las lineas, palabras y caracteres del stream.
También podemos hacer que stdout vaya a parar directamente ea un archivo:
Acá creamos el archivo manual-de-bash con el stdout de man bash después se lo pasamos por parámetro (esta vez no por stdin) a wc.
Una cosa más sobre bash que es importante en este momento. Bash permite definir variables. Por ejemplo:
export FOO=bar
Ahí definimos la variable FOO y le asignamos como valor la palabra bar (por que sí). Esto es útil porque después podemos leer el contenido de una variable:
$ echo $FOO
bar
echo no es más que otro programa, que sirve para mostrar una línea de texto y, como su nombre lo indica lo único que hace es repetir los que recibe. Acá, bash expandió la variable reemplazándola por su contenido antes de pasárselo a echo, y por eso pudimos leer el contenido en stdout.
De modo similar
$ echo ~
/home/pg/
Y
$ echo hola mundo
hola mundo
Bien!, hicimos nuestro primer “hola mundo!”. El tradicional programa, escrito en bash (más adelante vamos a ver otros lenguajes donde se complica un poco más…)
Muchas veces estas variables son para “configurar” cosas. Los programas pueden leerlas para usar sus valores. Bash también las usa. Por ejemplo, una bien conocida es la variable PATH, que podemos ver haciendo echo $PATH.
Cuando escribimos le nombre de un programa (ls, rm, mkdir, echo, wc, man, which, etc…) lo que hace bash es fijarse si encuentra físicamente el programa en el sistema de archivos. Pero no se fija en todo el sistema, se fija únicamente en los directorios listados en la variable PATH. Esto significa que si escribimos unos programas y queremos que al tipearlos bash los ejecute como hace con cualquier otro programa de los que vimos, entonces podemos, o bien mover nuestro programa a un directorio que aparezca listado en el path, o también podemos agregar al PATH un directorio donde tengamos nuestros programas. Por, ejemplo, si los tenemos en ~/bin podemos hacer
$ export PATH=$PATH:$HOME/bin
Con eso agregamos /home/pg porque HOME es otra variable de entorno cuyo contenido es justamente la carpeta home del usuario (igual que ~).
Así, para saber donde busca bash los ejecutables miramos el path. Pero para ver el path de un ejecutable usamos el programa which, que está en /usr/bin/:
$ which which
/usr/bin/which
grep
Tomemos por ejemplo el programa grep.
grep es un programa disponible en muchos de los sistemas operativos más comunes (me refiero en realidad a linux y mac, windows no lo trae). Lo que hace es básicamente buscar en el contenido de archivos por algún pattern que le interese al usuario y lo muestra en la pantalla la línea en la cual aparece, pudiendo dar también más información si así lo quisiera el usuario. Es bastante parecido a hacer Ctrl + f su interfaz básica es así: en una terminal hay que invocarlo “pasándole” el PATTERN y el archivo en el cual buscar. Por ejemplo, si tengo en un archivo llamado dict un diccionario y quiero ver la definición de interfaz, entonces escribo:
$ grep "interfaz:" dict
(Aclaración: el signo $ sólo indica que es un comando de bash pero sobre esto más adelante).
Esto me va a imprimir sólo esa línea. Pero pudo hacer algo para leer más. Supongamos que la definición se extienda por tres líneas, entonces:
$ grep -A3 "interfaz:" dict
Acá conviene hacer una pausa y mencionar una cosa. Al parecer, existen personas a las que les gusta más usar la terminal (también llamada consola o también línea de comandos), mientras que hay personas que prefieren la “interfaz gráfica” que involucra usar el mouse y un conjunto de menúes anidados. Probablemente podrían usarse un montón de programas para esta tarea que acá estamos describiendo: mostrar una línea que contenga. Pero quizá grep sea de todos si no el más sencillo, al menos tal vez el más específico, y por eso resulta un buen ejemplo.
Pero lo importante del ejemplo es lo siguiente (y vale, adaptado, para cualquier otro programa). Yo al menos, si bien soy usuario de grep, no conozco de memoria su interfaz (los ejemplos de arriba son una ínfima muestra nomas). De modo similar, el usuario de un programa que busque patterns en archivos con una interfaz gráfica probablemente tenga que desplegar los menúes para ver cómo ejecutar determinada acción. El usuario de grep (y esto vale para todos los comandos de unix -e incluye linux y mac) hará lo siguiente:
$ man grep
La entrada de man tiene 445 líneas mientras que la de grep 403 (esto en la versión particular que estoy usando ahora). man grep empieza así:
Como se ve, el nombre (en este caso se mencionan otros comandos “parecidos”) tiene una breve descripción de lo que hace el programa. Después viene una synopsis que muestra cómo se usa. Las partes entre corchetes de la synopsis vendrían a ser opcionales, los puntos suspensivos que podría haber más de una cosa de las que se enumeran. Después viene una descripción de cómo se usa. El archivo sigue mucho más. El punto es mostrar que como usuarios de aplicaciones, los programadores dependemos de las interfaces que éstas ofrecen. Y en particular, esta es una muy general en el entorno linux. man se usa para conocer el uso de cualquier programa. Por ser común tiene la ventaja de que hay que aprenderlo una sola vez. Si cada programa va a tener su propia forma de exponer su funcionalidad y su uso, entonces por cada programa vamos a tener que ver cómo es. Pero acá es siempre igual (o bastante parecido al menos…).
También puede pasar que ya leímos la entrada de man pero no nos acordamos algo puntual. Por ejemplo, nos acordamos que había una forma de hacer aparecer más de una sola línea pero no nos acordamos con qué letra (con que “opción” más precisamente) lo hacíamos. Para eso suele usare la opción --help como parámetro de nuestro comando: grep --help nos da:
Usage: grep [OPTION]... PATTERNS [FILE]...
Search for PATTERNS in each FILE.
Example: grep -i 'hello world' menu.h main.c
PATTERNS can contain multiple patterns separated by newlines.
Pattern selection and interpretation:
-E, --extended-regexp PATTERNS are extended regular expressions
-F, --fixed-strings PATTERNS are strings
-G, --basic-regexp PATTERNS are basic regular expressions
-P, --perl-regexp PATTERNS are Perl regular expressions
-e, --regexp=PATTERNS use PATTERNS for matching
-f, --file=FILE take PATTERNS from FILE
-i, --ignore-case ignore case distinctions in patterns and data
--no-ignore-case do not ignore case distinctions (default)
-w, --word-regexp match only whole words
-x, --line-regexp match only whole lines
-z, --null-data a data line ends in 0 byte, not newline
Miscellaneous:
-s, --no-messages suppress error messages
-v, --invert-match select non-matching lines
-V, --version display version information and exit
--help display this help text and exit
Output control:
-m, --max-count=NUM stop after NUM selected lines
-b, --byte-offset print the byte offset with output lines
-n, --line-number print line number with output lines
--line-buffered flush output on every line
-H, --with-filename print file name with output lines
-h, --no-filename suppress the file name prefix on output
--label=LABEL use LABEL as the standard input file name prefix
-o, --only-matching show only nonempty parts of lines that match
-q, --quiet, --silent suppress all normal output
--binary-files=TYPE assume that binary files are TYPE;
TYPE is 'binary', 'text', or 'without-match'
-a, --text equivalent to --binary-files=text
-I equivalent to --binary-files=without-match
-d, --directories=ACTION how to handle directories;
ACTION is 'read', 'recurse', or 'skip'
-D, --devices=ACTION how to handle devices, FIFOs and sockets;
ACTION is 'read' or 'skip'
-r, --recursive like --directories=recurse
-R, --dereference-recursive likewise, but follow all symlinks
--include=GLOB search only files that match GLOB (a file pattern)
--exclude=GLOB skip files that match GLOB
--exclude-from=FILE skip files that match any file pattern from FILE
--exclude-dir=GLOB skip directories that match GLOB
-L, --files-without-match print only names of FILEs with no selected lines
-l, --files-with-matches print only names of FILEs with selected lines
-c, --count print only a count of selected lines per FILE
-T, --initial-tab make tabs line up (if needed)
-Z, --null print 0 byte after FILE name
Context control:
-B, --before-context=NUM print NUM lines of leading context
-A, --after-context=NUM print NUM lines of trailing context
-C, --context=NUM print NUM lines of output context
-NUM same as --context=NUM
--group-separator=SEP print SEP on line between matches with context
--no-group-separator do not print separator for matches with context
--color[=WHEN],
--colour[=WHEN] use markers to highlight the matching strings;
WHEN is 'always', 'never', or 'auto'
-U, --binary do not strip CR characters at EOL (MSDOS/Windows)
When FILE is '-', read standard input. With no FILE, read '.' if
recursive, '-' otherwise. With fewer than two FILEs, assume -h.
Exit status is 0 if any line is selected, 1 otherwise;
if any error occurs and -q is not given, the exit status is 2.
Report bugs to: bug-grep@gnu.org
GNU grep home page: <http://www.gnu.org/software/grep/>
General help using GNU software: <https://www.gnu.org/gethelp/>
Esto es un resumen más breve que lo anterior.
En resumen man es tu amigo, Probablemente te venga bien para consultar no sólo programas (ya sean de consola o incluso gráficos) sino también syscalls del sistema operativo (es decir, la interfaz de la que hablábamos antes), funciones de algunos lenguajes y librerías (o bibliotecas) de esos lenguajes…
Pero a veces googlear es más fácil. ¿Por qué? Porque pasa mucho que la misma duda que tenemos es exactamente lo que ya preguntó alguien y re respuesta aparece concisa sin tener que leer mucho ni nada. Por ejemplo, googleamos (en inglés porque hay muchas más cosas en inglés hoy poy hoy al menos)
grep print more lines
y lo primero que trae el buscador es esta entrada de stackoverflow donde la respuesta marcada como válida es exactamente lo que necesitábamos saber. Esta pagina es muy usada y si la googleamos vamos a ver muchos memes, yo me acuerdo el del teclado con solo tres teclas: Ctrl, c y v.
Los patterns de grep
Si fuera sólo que grep encuentra una palabra quizá sería muy usado también, por el tema es que los patterns que busca no son solo palabras “textuales” sino que estas expresiones denotan conjuntos de cadenas. Me explico.
Una cadena (string) se refiere a una cadena de caracteres como aabbc o al9jdd;[' lo que es algo con lo que al programar estamos lidiando todo el tiempo. En todos los lenguajes de programación existen partes dedicadas a la manipulación de cadenas dada su utilidad.
Al buscar una palabra en un diccionario, como hace un rato, estamos buscando una cadena. Pero el diccionario entero es en sí una cadena. Un programa escrito es también una cadena. A tal punto que un lenguaje puede definirse como un conjunto de cadenas (de hecho así se lo define en las ciencias de la computación).
Todo esto hace que sea muy común tener que escribir programas que hagan cosas con cadenas, de ahí su ubiquidad en los lenguajes de programación.
Esos patterns que usa grep entonces “matchean” un conjunto de cadenas, podemos decir que denotan ese conjunto. Y, si definimos lenguaje como conjunto d ecadenas, entonces cada uno de estos patterns denotan un lenguaje. O, más en criollo, son un lenguaje.
Si escribo el pattern lenguaje entonces me refiero al lenguaje cuya única cadena es justamente la palabra lenguaje. Pero puedo escribir el pattern ... Este no es una única palabra sino que son todas las cadenas de dos caracteres. Porque el . representa cualquier caracter (incluyendo los signos de puntuación y cualquier otro). El único caracter que no incluye es el de quiebre de línea, pero est oes porque grep busca línea por línea, y por ende actúa como si no estuvieran.
Estos patterns que usa grep se llaman expresiones regulares y se abrevia regex (de regular expressions).
Hay muchos lugares donde se explica qué son y cómo se usan las regex (no siempre se las usa de la misma manera, porque a veces cambian las convenciones, pero el concepto en sí es el mismo) y uno de esos lugares es el manpage de grep (manpage es la entrada de man grep).
Como muchas cosas en programación, es raro que uno se ponga a estudiar exhaustivamente la interfaz de regex de grep o cualquier otro programa o lenguaje que las use. Lo común es leer un poco cuando se lo necesita y de a poco ir aprendiendo el tema.
Como ya puse en otro posteo anterior, la idea del blog es que sea como un tutorial para aprender a programar dirigido a quienes quieran empezar “de cero”. Lógicamente, esto supone un orden de los posteos, si bien el orden no es necesarioamente total: es decir puede ser que haya una dependencia de alguno respecto de algún otro (sin el cual no se pueda entender), así como puede haber posteos independientes entre sí en este sentido. Para que sea más fácil para mí, voy simplemente a ir subiendolos a medida que los escriba, aunque tratando de hacer esto respetando ese orden, y también de indicar esas dependencias con enlaces. Si tiene sentido veo de poner un índice.
Y como este es el punto de partida voy a empezar con lo que me pareció lo más básico de todo: ¿con qué programar? Porque si alguen va a empezar tiene que saber qué necesita y si está pensando en si hacerlo o no, también. Como puede que me extienda un poco en esto probablemente haga varios posteos al respecto. Por el momento me interesa destacar que la respuesta a esta pregunta, como tantas otras, depende del momento en que se haga.
Con el paso del tiempo se va haciendo más fácil aprender a programar. Recuerdo cuando trajeron la primera computadora a mi casa sin que existiera conexión a internet. Al prenderla se veía algo como:
C:\>_
El vendedor les había explicado a mis padres como abrir los programas que traía y sólo teníamos un manual que en la tapa decía IBM y que no se entendía nada (al menos para mí en ese entonces, con alrededos de 10 años). El principal uso que yo le daba era jugar una truco que tenía que se caracterizaba por el sonido de “la cumparsita”. La verdad que no era tan común tener una computadora en esa época y menos todavía gente que aprenda a programar.
Lo que hizo que todo cambie y permitió que surgieran tantos programadores es sin duda no solo que se abarataron las computadoras si no que cada vez es más fácil obtener los conocimientos necesarios para aprender. Este punto es clave: no es tan importante lo que uno sepa como la accesibilidad de lo que uno necesite saber.
Y esto se ve reflejado no sólo en qué permitió el crecimiento del número de programadores. También, por ejemplo, en la velocidad con que cambian las cosas. En pocos años se empieza a adoptar un lenguaje mientras otro se va usando menos, o aparecen formas nuevas de hacer las cosas. También surgen nuevas “tecnologías” que es necesario aprender o programas y herramientas se empiezan a usar y hay que aprender a hacerlo.
Así, esto de ir asimilando nuevos conocimientos es clave para programar, incluso más que la capacidad de retener conocimientos ya adquiridos.
Por otra parte, por su puesto, existen aquellos conocimientos que no cambian, y son las teorías que permitieron y permiten el desarrollo de la computación. Incluyo acá a cosas como la computación cuántica, las maquinas de Turing, la complejidad algorítmica, etc. Por su puesto para aprender todo esto en profundidad conviene ir a la universidad en vez de simplemente buscar posteos en internet (aunque muchas veces ayudan eh).
El enfoque que voy a adoptar, entonces, es práctico y tiene por objetivo orientar con las condiciones básicas que necesita un programador para empezar. Entre estas condiciones hay unas subjetivas, como la disposición a aprender y a resolver los problemas y las cuestiones que van surgiendo. También hay objetivas, como tener una computadora y tener internet.
Así que bueno, vamos a asumir que la disposición a aprender existe, y que hay una conexión a internet y una computadora.
De esas tres condiciones es la más importante sin duda la primera. Por ejemplo, uno podría programar sin internet buscando información en otro lugar. Incluso sin una computadora uno podría aprender a programar. De hecho hay algoritmos famosos que se inventaron antes que las computadores como el algoritmo de Euclides y la criba de Eratóstenes. Y sin ir más lejos el método de multiplicación que aprendemos en el colegio es un algoritmo que ejecutábamos nosotros mismos usando el papel como memoria ram y nuestra memoria (de las tablas) como procesador… Y aprender sobre algoritmos también es aprender a programar.
Algoritmos y programas
Existe una (quizá sutil) diferencia entre lo que es un programa y lo que es un algoritmo. Un programa es algo que puede ejecutar una máquina, tan simple como eso. Si configuro (o seteo usando un anglicismo común) el lavarropas para que extienda el lavado durante cierta cantidad de tiempo y a cierta temperatura, con (o sin) centrifugado, estoy, claramente, programando.
De la misma manera, las computadoras suelen tener un set de instrucciones y los programas que corren básicamente le van diciendo qué instrucción ejecutar en cada momento. Sin embargo, son muy pocos los programadores que conocen todas las instrucciones que tiene la maquina, que son realmente muuchas ver, por ejemplo esto.
Los programadores, hoy por hoy, usan lenguajes de programación que son muy distintos al set de instrucciones de la computadora (llamado assembly) y muchos más fáciles de entender. En realidad, algunos se parecen más y otros menos, pero ninguno se parece demasiado. De hecho, uno podría decir que apretar Ctrl + f para buscar una palabra en una página de internet es darle una instrucción a la computadora para que haga algo, y uno lo hace sin tener ni idea de cuáles son las instrucciones del set de instrucciones que se están usando para eso.
Este último punto es muy importante: no es necesario saber cómo funciona internamente algo para poder usarlo. Hay que conocer sólo su funcionalidad. Si aprendemos, por ejemplo, python, no necesitamos aprender el instruction set de lo procesadores de intel, porque esto ya está hecho y resuelto en otro nivel, adentro del lenguaje mismo. Y esto aplica a todo.
Por otra parte, un algoritmo no necesariamente está escrito para poder correr en una computadora. Por ejemplo, uno cuando hace una multipliación con lapiz y papel está siguiendo un algoritmo, y no hay ninguna computadora involucrada. Pero el algoritmo es una sucesión de pasos a seguir que sirven para resolver un problema. Entonces, podemos escribir un programa para que una computadora resuelva un problema siguiendo un algoritmo.
Una cosa más, porque hoy en día se usa mucho la palabra algoritmo en un sentido que es un poco distinto: por ejemplo en “el algoritmo me sugiere cosas que no me gustan”. Bueno, acá estaríamos suponiendo que la computadora (el celular) está corriendo un programa que sigue un algoritmo que determina que recomendar. Pero en este caso estamos probablemente hablando de machine learning. Y si bien esos programas son programas como cualquier otro que terminan dando una a una una serie de instrucciones a la computadora, esos algoritmos muchas veces son algoritmos heurísticos y se diferencias porque a veces resignan la solución exacta a un problema por una aproximación.
Nosotros vamos a empezar (como es habitual) con los algoritmos que simplemente dan los pasos para la solución correcta de un problema (léase pregunta) y después hablaremos, quizá, de las heurísticas.
Así, programar es para nosotros hacer que la computadora resuelva algo: primero tenemos un problema, por ejemplo, dados dos números, obtener la suma de ambos. Después el algoritmo que lo resuelve. Por ejemplo:
1. Disponer los números uno arriba del otro
alineados a la derecha.
Por ejemplo si los números son 42 y 1359:
// 42
// 1059
2. Recorer los dígitos de derecha a izquierda
de la siguiente manera:
2.a Sumar los dos dígitos (si hay uno solo
tomar ese)
2.b Si la suma es menor a 10 (o sea es un sólo
digito) entonces en la fila del resultado
escribir ese número en la column aque va.
Si la suma es mayor que 9 (en tal caso es
entre 10 y 18), entonces sumar uno a la
columna siguiente y dejar el digito de la
derecha en la fila con el resultado en la
columna correspondiente.
Usando el mismo ejemplo:
// 11 <-- "carry" o lo que me llevo
// 42
// 1059
// ----
// 1101
Acá en los libros de ciencias de la computación suele venir la parte donde se demuestra que el algoritmo es correcto, es decir, que computa exactamente la respuesta buscada. En la práctica del programador esto suele ser menos habitual. Primero porque a veces se usan algoritmos ya demostrados, a veces porque la demostración “formal” sería muy engorrosa y es muy fácil convencerse intuitivamente de que es correcto, a veces porque tenemos tests que prueban ese algoritmo que nos dan un poco de seguridad.
Estos tests básicamente consisten en correr el programa alimentándolo con distintos valores para los cuales ya sabemos la respuesta (o sea, la conocemos independientemente del programa, porque lo calculamos a mano o usamos otro programa que ya está chequeado) y entonces comparamos el resultado esperado con el resultado del programa. Esto no nos garantiza un ciento por ciento que el programa es correcto (como sí lo haría una demostración formal) pero es la práctica habitual en la industria.
Con esto no sólo podemos detectar si un algoritmo es incorrecto (un resultado positivo no nos garantiza que esté bien, pero uno negativo nos garantiza que está mal), también no advierte muchos errores en el programa que no son del algoritmo, si no que tipeamos algo mal, o al llevarlo a un lenguaje de programación particular una parte no quedo reflejando exactamente lo que el algoritmo decía que había que hacer. Es decir, por más que se haya demostrado que el algoritimo es correcto, al implementarlo podemos hacer algo mal.
Esto es importante. Además del problema y el algoritmo, necesitamos el lenguaje de programación. Dependiendo del lenguaje el programa va a ser muy diferente. Pero antes de empezar a hablar de los lenguajes (los más habituales hoy en día) vamos a considerar algunas otras cuestiones “preliminares” en la siguiente sección como qué usar para escribir esos programas, qué usar para ejecutaros…
En fin, además de una computadora e internet, es necesario algo en qué aplicar la programación. Si no puede que resulte muy aburrido. Y como al aprender uno hace cosas “de juguete” estamos hablando de aplicaciones simples, no rocket science. Y entre los requerimientos más concretos, aparte de la compu e internet, incluiría el sistema operativo (q por lo general viene con la máquina), un editor de texto, un compilador (o un intérprete si el leguaje es “interpretado”), un control de versiones y, por qué no, un debbuger. Así que en los próximos posteos seguimos con los preparativos…
Como lo indica su nombre la idea es hablar de funciones. Pero en particular de funciones que funcionan. Qué quiere decir esto? Bueno, más allá del juego de palabras, el punto con el nombre es destacar el hecho de que en la computación las funciones no son como en la matemática. En la matemática, se puede definir una función o hablar de funciones sin siquiera tener un método efectivo para poder evaluarla. Poniendo un ejemplo concreto, tenemos la función que es bien conocida: la raíz cuadrada.
Desde el punto de vista matemática, si especificamos su dominio y codominio correctamente queda con eso bien definida y se puede usar para demostrar propiedades, y demás cosas que hacen los matemáticos. El problema es que esa función no «funciona» sólo por escribirla. Y digo que no funciona en el sentido de que no calcula. O sea, si queremos conocer f(2022), por ejemplo, tenemos que calcularlo de alguna manera y la definición de la función, así como está, no nos dice cómo. En este caso en particular el problema es más grave aún porque la respuesta tendrá tantos decimales que no nos va a quedar otra que conformarnos con una aproximación.
Así, no son las funciones matemáticas las que nos interesan (bueno, sí nos interesan, pero se entiende), sino las que podemos llamar programas. Son programas, digamos, las que una vez que reciben su o sus argumentos se pueden ejecutar con la esperanza de que devuelvan un resultado útil.
Digo con la esperanza porque puede ocurrir que no terminen, es decir, se cuelguen. En general parece que un programa que se cuelga es porque está mal hecho. Pero puede ocurrir que en realidad no se colgaba y faltaba esperar un poco más, y también pude ocurrir que efectivamente se colgaba y que esa era la idea, justamnte que se cuelgue en ese caso. Así que no necesariamente hay que decir que no funcionan las funciones que se cuelgan.
También hay funciones, en el sentido matemático, que no se pueden computar, o sea que no se pueden «programar». El ejemplo más conocido es HALT. Esta función recibe recibe 2 argumentos: un programa y una entrada (para dicho programa) y nos devuelve «si», si es que ese programa con esa entrada termina, y «no» en caso contrario.
Y si bien este tipo de cosas forman parte de las ciencias de la computación, en la industria estamos en general dando vueltas en torno a problemas computables (después de todo es lo único que podemos entregar).
Esta idea de función hoy es bastante central en los lenguajes de programación, pero esto no siempre fue tan así. Hoy se usan lenguajes cono conocidos como «de alto nivel»: C, C++, java, python, Haskell, etc. Si bien algunos dicen que C es bajo nivel, es porque se usa el término en un matiz un poco distinto al que tenía en un principio, cuando el lenguaje era el lenguaje de la maquina, el assembly. Escribir en assembly es básicamente agarrar el manual de instrucciones de la maquina e ir dictando uno por uno los pasos a seguir, eso es bajo nivel. Pero en los años 50 (más o menos) surgieron los primeros compiladores. Con las gramáticas generativas, el desarrollo de un compilador se simplificó drásticamente y empezaron a aparecer distintos lenguajes y compiladores. Los compiladores lo que hacen es tomar un «programa» escrito siguiendo una sintaxis determinada, y lo traduce al lenguaje de una maquina. Con los compiladores, entonces, subimos el nivel de abstracción, ya no pensamos en las operaciones que la máquina tiene que ejecutar si no en conceptos más útiles para la tarea de diseñar software. Por ejemplo, la idea de función. Hoy por hoy se suele decir que C es de bajo nivel pero porque lo es en comparación por ejemplo a Haskell, que cuenta con muchas más abstracciones. Por ejemplo, en Haskell podemos aplicar parcialmente una función, es decir agarrar una función y fijarle «on the fly» uno de sus parámetros para después usarla así. C no permite esta y muchas otras cosas (si bien uno podría hacer cosas para obtener resultados iguales, el código termina siendo mucho más complicado.
Pero tampoco es que la función surgió directamente o de una vez por todas. Lo que sucede es que los programadores pensaron una forma de evitar tener que repetir un mismo bloque de código cada vez que sea necesario repetir que la maquina ejecute una misma tarea. Es decir, en vez de escribir nuevamente las mismas instrucciones cada vez, hacer algo para que el programa las ejecute pero sin tener ni que reescribirlas ni copypatearlas. En interesante que bien al principio ni las maquinas ofrecían esa funcionalidad ni los lenguajes. Lo que hicieron fue llamar subrutinas a esos bloques reutilizables y para poder reutilizarlos tenían que escribir el código que le pasaba el control a la subrutina (con algún argumento quizá) y volvía después al programa principal. Esa parte se llamaba subroutine linkage. (bueno, las primeras subrutinas ni eso, al principio ya el mero copy y paste era mejor que reescribir no sólo porque es menos tiempo, si no porque darle una función a un bloque, es decir que «haga tal cosa» ayuda a que el código sea más ordenado. Aparentemente, la primer subrutina se escribió para la Harvard Mark I por Grace Hooper en 1944 y lo que hacía era calcular la función seno, pero era una subrutina abierta, para ser insertada en el código que la vaya a usar en lugar de dinámicamente linkeada).
Una ventaja obvia de las subrutinas es que achicaba el tamaño de los programas: si vemos cuánta memoria se podía usar en esa época vemos que era definitivamente una ventaja. Pero mucho más que eso lo que las subrutinas tienen de bueno son dos cosas:
permiten entender mejor la complejidad del código
permiten escribir «bibliotecas» (libraries en inglés, correctamente es bibliotecas en castellano pero muchas veces se dice «librerías» quizá porque los programadores no somos de letras).
La segunda ventaja es muy importante desde el punto de vista práctico, pero la primera es fundamental para el progreso de la disciplina (bueno, las dos lo son). Imagínense un choclo de código en assembly sin siquiera subrutinas, con bloques repetidos por doquier y ni si quiera identificados. Nadie quiere mantener eso y con razón.
Ahora bien entre las instrucciones de la computadora están los jumps absolutos o goto que lo que hacen es permitirnos saltar de una instrucción a cualquier parte del programa, indicando simplemente la línea a la que queremos ir. Una célebre nota del no menos célebre Edgar Dijkstra ha terminado sepultando el goto en los lenguajes de alto nivel.
Resumiendo el tema es así. Si tenemos gotos podemos saltar de cualquier parte del código a cualquier otra haciendo caótico seguir el curso de la ejecución por ejemplo al debugguear y por ende entender el programa. Entonces, si sacamos los gotos sabemos que uno sigue la ejecución hasta llegar al llamado a una subrutina y al fin de la misma (o a lo sumo a un return) vuelve de donde la había llamado.
En fin, hay muchos temas que venimos mencionando medio al pasar y la idea es quizá dedicarle un post a cada uno más adelante. Acá me quería centrar simplemente en el tema del blog, que es la programación con funciones. Sólo voy a agregar unos comentarios más.
Las funciones en sentido matemático tienen algunas características que las hacen bien distintas a las subrutinas (o incluso a las funciones de lenguajes como C o python, los llamados imperativos) y que sin embargo son muy deseables en la programación. Estas son la transparencia referencial y la inexistencia de efectos secundarios.
El segundo punto es bastante obvio, como las funciones matemáticas no ejecutan, tampoco van a ejecutar algo más de los que definen (por que no ejecutan nada, menos van a ejecutar de más). En cambio, una subrutina puede devolver un valor, pero además hacer cosas como mandárselo para que imprima la impresora o se guarde en una base de datos o cualquier otra cosa. Peor aún, pueden leer algo de una base de datos o esperar a que un usuario les provea algo, y en ese caso esas cosas podrían no pasar dando lugar a excepciones…
La transparencia referencial lo que dice es que siempre podemos reemplazar la función con su(s) parámetros por el valor correspondiente y el programa no se va a ver afectado por eso. Veamos un ejemplo donde esto no pasa. Hay una función de C que se llama rand que nos da un número aleatorio. La función no tiene parámetros, pero no podemos reemplazar rand por una valor porque, básicamente, no es una función (en sentido matemático, ya que las funciones matemáticas siempre asignan un mismo valor a un mismo argumento, y si no tienen argumentos deben ser constantes).
En computación, las funciones que cumplen con estas dos cosas se llaman funciones puras. Las funciones puras son muy buenas, comparándolas con las que no lo son, ya que, nuevamente, hacen más fácil analizar, entender, debuggear un programa. Y mientras más complicados son los programas, más bugs se nos pasan por alto y más tiempo estamos «fixeando» y más difícil es hacerlo …
Empiezo este blog para escribir sobre programación. Por un lado, espero que pueda servir para quien quiera empezar a programar, porque pienso ver temas básicos útiles para los que se inicien en este oficio. Por otra parte, también pueda que le interese al que ya tenga experiencia programando ya que podrá leer opiniones y puntos de vista que incluso lo podrán motivar a contrastar los propios, dado que pretendo incluir también cuestiones más generales.
Supongo que resultará un blog eminentemente pragmático, pues va a tomar como punto de partida la experiencia diaria de programar, aunque en este oficio (al menos) la teoría es inherente a la práctica, y uno tiene que estar leyendo para ir entendiendo y resolviendo los problemas que se van dando.
La programación es para algunos un arte, al menos lo es para Donald Knuth y creo que con razón. Involucra conocimientos teóricos, como por ejemplo sobre complejidad algorítmica y sobre estructuras de datos, conocimientos prácticos, incluyendo la habitualidad usando la sintaxis de un lenguaje de programación, o hasta la habilidad para encontrar los algoritmos eficientes para los problemas planteados, etc.
Y constituye una forma de ganarse la vida que puede resultar muy divertida si en cierto grado matchean los problemas que haya que ir resolviendo con las habilidades y el conocimiento adquiridos.
En fin, espero que al menos le pueda servir al que quiera empezar para facilitar los primero pasos.

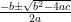



 que es bien conocida: la raíz cuadrada.
que es bien conocida: la raíz cuadrada.
